مشکل در پردازش تصویر با اعداد فارسی
برای رفع مشکل تشخیص اعداد فارسی چه کاری باید بکنم؟
از لایبرری های opencv ورژن 3.4.9 و tesseract ورژن 3.05.01 برای خوندن اعداد از روی عکس استفاده می کنم
برای تصاویر کوچک و کمی بی کیفیت مثل این
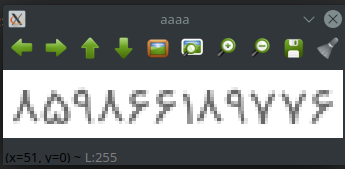
با تشخیص عدد 1 مشکلی دارم و معمولا یک رو با | یا الف اشتباه می گیره.
کاراکتر های اعداد فارسی رو به عنوان وایت لیست معرفی کردم و بقیه کاراکتر ها ازجمله | و الف رو به عنوان بلک لیست معرفی کردم و حالت تشخیص رو هم روی numeric گزاشتم.
بعد از این کار عکس بالا رو
"859866799776"
میخونه، یعنی عدد یک رو همراه با هشت کنارش اشتباه خونده و عدد 18 رو 79 متوجه شده
برای پیش پردازش هم به علت ریز بودن نوشته و کیفیت پایین اون فقط میتونم قسمت مورد نیاز رو از عکس اصلی کراپ کنم و بعد اون رو morphology کنم.
وقتی هم که عکس رو morphology می کنم به همچین حالتی تبدیل میشه و با عدد 9 اشتباه گرفته میشه (فقط الان چون میخواستم اینجا توضیح بدم عدد یک رو به سیاه تغییر دادم ولی در حالت اصلی پسزمینه سیاه هست و یک سفید )

البته مورد دیگه ای که فکر می کنم مشکل رو حل کنه و هنوز تست نکردم معرفی فونت هست و مشکلم اینه که نمیدونم در مرحله پیش پردازش برای تصحیح تصویر باید فونت رو معرفی کنم یا در مرحله تشخیص. کدوم نتیجه بهتری میده؟ (اصلا این رو چجوری باید انجام بدم؟)
به غیر از معرفی فونت چه راه های دیگه ای هست؟
گزینش سوالات
گفت و گو های مرتبط
دسته بندی سوالات
تگهای محبوب
