
خلاصه اولیه: Node یک پلتفرم همه کاره است، اما یکی از مصارف غالب آن، ساخت پردازشهای شبکه شده میباشد. در این مقاله، ما بر روی profile کردن رایجترین این موارد تمرکز خواهیم کرد: وب سرورهای HTTP.
اگر برای مدت کافی در حال ساخت هر چیزی با استفاده از Node.js بوده باشید، پس بدون شک درد مشکلات مربوط به سرعت غیر منتظره را تجربه کردهاید. JavaScript یک زبان بر پایه رویداد، و ناهمگام است. این مسئله میتواند استدلالی برای پیچیدگی کارایی در آن باشد، که به زودی واضح خواهد شد. معروفیت صعودی Node.js، نیاز به ابزارها، تکنیکها و تفکر مناسب برای محدودیتهای JavaScript سمت سرور را به وجود آورده است.
وقتی که به کارایی میرسیم، چیزی که در مرورگر نتیجه میدهد، لزوما برای Node.js مناسب نیست. پس چگونه مطمئن میشویم که یک پیادهسازی Node.js سریع بوده، و برای هدف ما مناسب است؟ بیایید یک مثال را بررسی کنیم.
به بخش اول این مقاله خوش آمدید. در ادامه با ما همراه باشید...
ابزار
Node یک پلتفرم همه کاره است، اما یکی از مصارف غالب آن، ساخت پردازشهای شبکه شده است. در این مقاله، ما بر روی profile کردن رایجترین این موارد تمرکز خواهیم کرد: وب سرورهای HTTP.
ما به یک ابزار نیاز خواهیم داشت که بتواند یک سرور را با تعداد زیادی درخواست پر کند، درحالیکه کارایی آن را اندازه میگیرد. برای مثال، ما میتوانیم از AutoCannon استفاده کنیم:
npm install -g autocannonابزار معیار سنجش خوب دیگر برای HTTP، ابزاری مانند Apache Bench (ab) و wrk2 میباشند، اما AutoCannon در Node نوشته شده است، فشار بارگذاری مشابهی (و گاهی بهتر) را فراهم میکند، و نصب آن بر روی ویندوز، لینوکس و Mac OS X بسیار ساده است.
اگر ما پس از این که یک اندازهگیری کارایی پایه را مستقر کردهایم، تصمیم بگیریم که روند ما میتواند سریعتر باشد، به راهی برای diagnose کردن مشکلات در حین پردازش نیاز خواهیم داشت. یک ابزار عالی برای تشحیص مشکلات کارایی مختلف، Node Clinic است، که میتواند با استفاده از npm نصب شود:
npm install -g clinicدر واقع این دستور یک مجموعه ابزار را نصب میکند. ما در طی مسیر خود از Clinic Doctor و Clinic Flame استفاده خواهیم کرد.
نکته: ما برای این مثال به Node 8.11.2 یا بالاتر نیاز خواهیم داشت.
کد
مثال ما یک سرور REST ساده، با تنها یک منبع است: یک محموله JSON بزرگ که به عنوان یک مسیر GET در /seed/v1 در معرض قرار گرفته است (یا در اصطلاح expose شده است). این سرور یک پوشه به نام app میباشد که از یک فایل package.json (بر پایه restify 7.1.0)، یک فایل index.js و یک فایل util.js تشکیل میشود.
فایل index.js سرور ما چنین ظاهری دارد:
'use strict'
const restify = require('restify')
const { etagger, timestamp, fetchContent } = require('./util')()
const server = restify.createServer()
server.use(etagger().bind(server))
server.get('/seed/v1', function (req, res, next) {
fetchContent(req.url, (err, content) => {
if (err) return next(err)
res.send({data: content, url: req.url, ts: timestamp()})
next()
})
})
server.listen(3000)این سرور نماینده موقعیت رایج تحویل محتویات دینامیک cache شده توسط client است. این هدف با استفاده از میانافزار etagger تحقق مییابد، که هِدِر ETag را برای آخرین state محتویات، محاسبه میکند.
فایل util.js قطعات پیادهسازیای را فراهم میکند که به طور رایج در سناریوهای این چنینی، در یک تابع برای گرفتن محتویات مرتبط از یک backend، میانافزار etag و یک تابع زمانی که نشانههای زمانیای را بر یک اساس دقیقه به دقیقه فراهم میکند، استفاده میشوند:
'use strict'
require('events').defaultMaxListeners = Infinity
const crypto = require('crypto')
module.exports = () => {
const content = crypto.rng(5000).toString('hex')
const ONE_MINUTE = 60000
var last = Date.now()
function timestamp () {
var now = Date.now()
if (now — last >= ONE_MINUTE) last = now
return last
}
function etagger () {
var cache = {}
var afterEventAttached = false
function attachAfterEvent (server) {
if (attachAfterEvent === true) return
afterEventAttached = true
server.on('after', (req, res) => {
if (res.statusCode !== 200) return
if (!res._body) return
const key = crypto.createHash('sha512')
.update(req.url)
.digest()
.toString('hex')
const etag = crypto.createHash('sha512')
.update(JSON.stringify(res._body))
.digest()
.toString('hex')
if (cache[key] !== etag) cache[key] = etag
})
}
return function (req, res, next) {
attachAfterEvent(this)
const key = crypto.createHash('sha512')
.update(req.url)
.digest()
.toString('hex')
if (key in cache) res.set('Etag', cache[key])
res.set('Cache-Control', 'public, max-age=120')
next()
}
}
function fetchContent (url, cb) {
setImmediate(() => {
if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404}))
else cb(null, content)
})
}
return { timestamp, etagger, fetchContent }
}این کد به هیچ وجه نمیتواند مثالی از یک شیوه برتر باشد! چندین نشانه از مشکلات عمیقتر در این کد وجود دارند، اما ما همینطور که برنامه را اندازه گرفته و profile میکنیم، آنها را خواهیم یافت.
برای این که یک منبع کامل به عنوان نقطه شروع خود داشته باشیم، یک سرور را میتوانید در این لینک بیابید.
Profile کردن
در جهت profile کردن، ما به دو ترمینال نیاز خواهیم داشت؛ یکی برای شروع برنامه، و دیگری برای آزمایش بارگذاری آن.
در یکی از ترمینالها و در داخل پوشه app، ما میتوانیم این کد را اجرا کنیم:
node index.jsدر ترمینال دیگر، ما میتوانیم آن را به این صورت profile کنیم:
autocannon -c100 localhost:3000/seed/v1این کار ۱۰۰ ارتباط همزمان را باز کرده، و سرور را برای ۱۰ ثانیه پر از درخواست خواهد کرد.
نتیجه نهایی باید چنین چیزی باشد (اجرای آزمایش دهم در http://localhost:3000/seed/v1 - ۱۰۰ ارتباط):
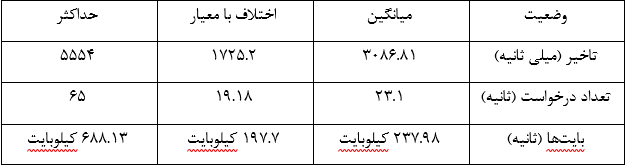
این نتیجه بر پایه دستگاه مورد استفاده شما، متفاوت خواهد بود. گرچه، با در نظر گرفتن این که یک سرور Node.js «سلام دنیا»، به سادگی قادر به انجام ۳۰.۰۰۰ درخواست بر ثانیه بر روی دستگاهی که این نتایج را تولید کرد میباشد، ۱۲ درخواست بر ثانیه با میانگین تاخیری که از ۳ ثانیه بیشتر میشود، ناراحت کننده است.
Diagnose کردن
کشف ناحیه مشکل
با تشکر از دستور Clinic Doctor، ما میتوانیم برنامه را با تنها یک دستور diagnose کنیم. در داخل پوشه app، ما این دستور را اجرا میکنیم:
clinic doctor --on-port=’autocannon -c100 localhost:$PORT/seed/v1’ -- node index.jsاین دستور یک فایل HTML خواهد ساخت که به طور خودکار وقتی که profile کردن به اتمام رسیده است، در مرورگر ما باز خواهد شد.
نتایج نهایی باید چیزی به مانند این مورد باشند:
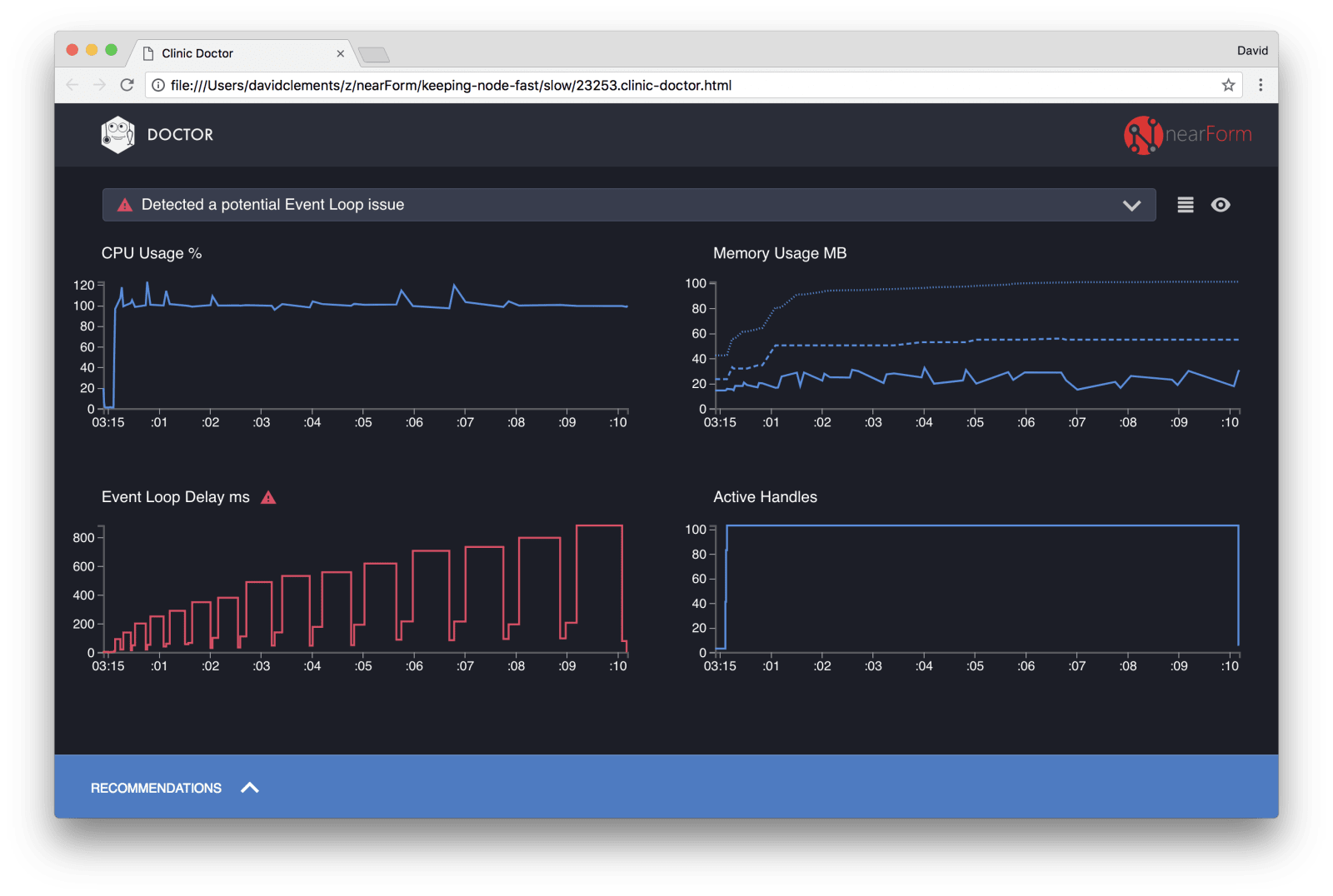
Doctor به ما میگوید که ما احتمالا یک مشکل در حلقه رویداد (Event Loop) خود داشتهایم.
در کنار پیغام نزدیک به بالای رابط کاربری، ما همچنین میتوانیم ببینیم که نمودار حلقه رویداد قرمز بوده، و یک تاخیر را نشان میدهد که دائما در حال افزایش است. قبل از این که عمیقتر به معنای آن وارد شویم، بیایید تاثیری که مشکل diagnose شده بر روی معیارهای دیگر دارد را درک کنیم.
ما میتوانیم ببینیم همینطور که فرآیند مربوطه پیش میرود تا درخواستهای صف بندی شده را پردازش کند، میزان استفاده از CPU دائما برابر با، یا بالای ۱۰۰ درصد است. موتور جاوااسکریپت Node (V8) در واقع از دو هسته CPU استفاده میکند، زیرا این دستگاه یک دستگاه چند هستهای است و V8 از دو thread استفاده مینماید. یکی برای حلقه رویداد (Event Loop)، و دیگری برای Garbage Collection. وقتی که در برخی مواقع میبینیم میزان استفاده از CPU به ۱۲۰ درصد میرسد، این پردازش در حال جمعآوری آبجکتهایی مربوط به درخواستهای رسیدگی شده میباشد.
ما میتوانیم این همبستگی را در نمودار حافظه ببینیم. خط توپر در نمودار حافظه، معیار Heap Used (نمایانگر توده استفاده شده) است. هر زمان که جهشی در CPU وجود دارد، ما میتوانیم سقوطی را در خط Heap Used ببینیم، که نشان میدهد میزان مصرف حافظه کم شده است.
Active Handleها تحت تاثیر تاخیر حلقه رویداد قرار نمیگیرند. یک Active Handle، آبجکتی است که یا I/O و یا یک تایمر را نشان میدهد. ما به AutoCannon دستور دادیم که ۱۰۰ ارتباط را باز کند. Active Handleها پس از شمارش ۱۰۳ توقف میکنند. سه handle اضافه مربوط به STDOUT، STDERR و handle مربوط به خود سرور هستند.
اگر بر روی پنل Recommendations در پایین صفحه کلیک کنیم، باید چنین چیزی را ببینیم:
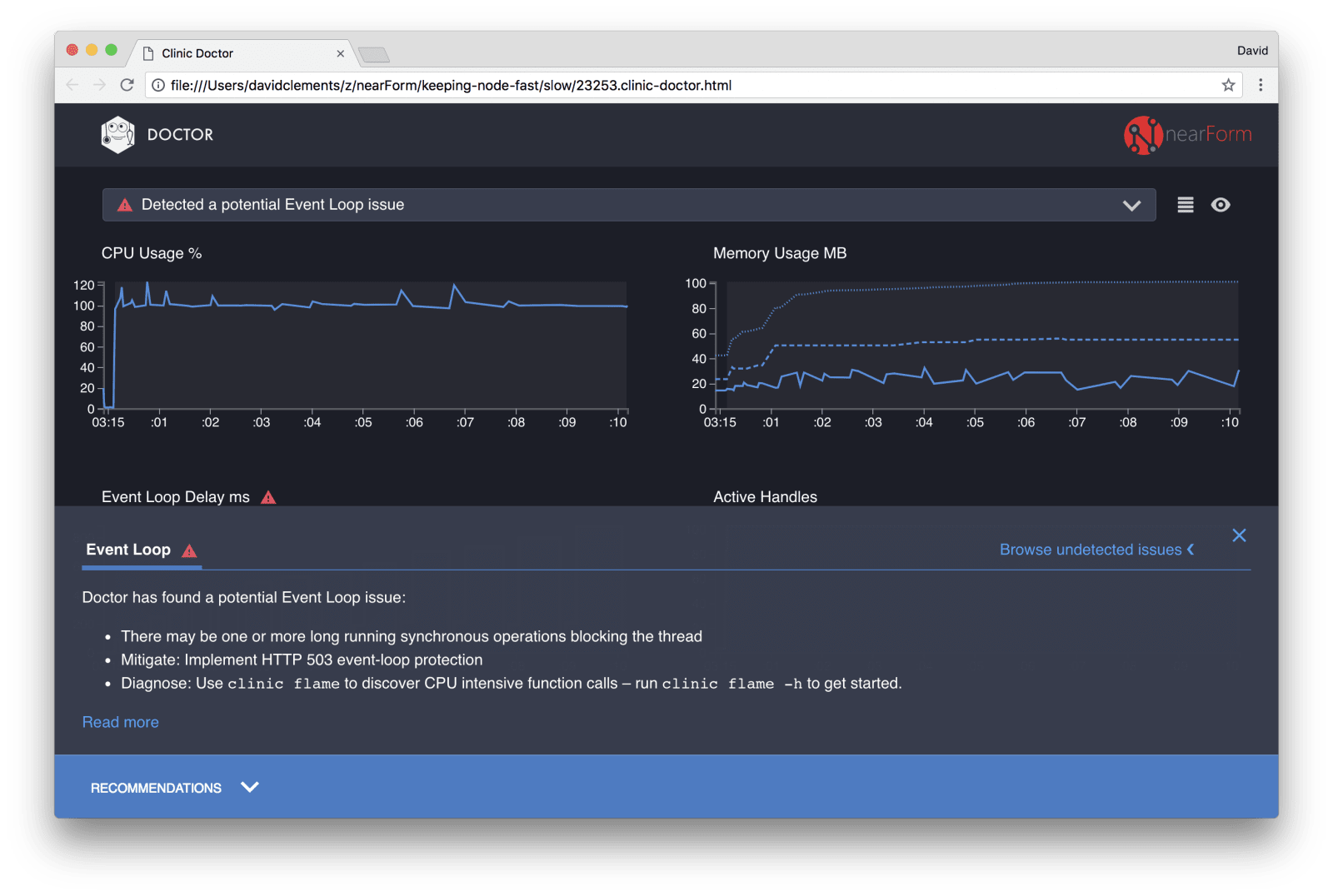
تسکین کوتاه مدت
تجزیه و تحلیل علت هستهای مشکلات کارایی، میتواند زمانبر باشد. در مورد یک پروژه مستقر شده و زنده، اضافه کردن حفاظت اضافه به سرورها یا سرویسها، ارزشش تلاشش را دارد. هدف از حفاظت بیش از حد، این است که تاخیر حلقه رویداد را بازرسی کنیم و اگر یک threshold منتقل شد، یک پاسخ «503 Service Unavailable» را برگردانیم. این کار به یک متعادل کننده بار اجازه میدهد تا در مقابل نمونههای دیگر شکست بخورد، یا در بدترین شرایط یعنی این که کاربر باید برنامه را refresh کند. ماژول حفاظت اضافی (overload-protection module) میتواند این هدف را با کمترین کد اضافی برای Express، Koa و Restify فراهم کند. فریموورک Hapi مقدار زیادی تنظیمات پیکربندی بارگذاری را به همراه دارد که همین نوع حفاظت را فراهم میکنند.
درک ناحیه مشکل
طبق توضیح کوتاه Clinic Doctor، اگر حلقه رویداد تا سطحی که ما در حال مشاهده آن هستیم تاخیر خورده باشد، احتمال این که یک یا چند تابع در حال مسدود کردن حلقه رویداد باشند، بسیار بالاست.
تشخیص این مشخصههای اولیه JavaScript، به خصوص برای Node.js مهم است؛ زیرا رویدادهای ناهمگام تا زمانی که کد فعلی کامل نشده است، نمیتوانند بروز دهند.
به همین علت است که یک تابع setTimeout نمیتواند دقیق باشد.
برای مثال، با اجرای این کد در DevTools یک مرورگر یا Node REPL:
console.time('timeout')
setTimeout(console.timeEnd, 100, 'timeout')
let n = 1e7
while (n--) Math.random()نتایج اندازهگیریهای نهایی هیچ وقت برابر با ۱۰۰ میلی ثانیه نخواهند بود. به احتمال زیاد این نتایج در محدوده ۱۵۰ میلی ثانیه تا ۲۵۰ میلی ثانیه خواهند بود. setTimeout یک عملیات ناهمگام (console.timeEnd) را برنامهریزی کرد، اما کدی که در حال حاضر موجود است، هنوز کامل نشده است و هنوز دو خط دیگر وجود دارند. کد فعلی، همچنین تحت عنوان «تیک» فعلی شناخته میشود. در جهت این که تیک ما کامل شود، Math.random باید ۱۰ میلیون بار فراخوانی شود. اگر این کار ۱۰۰ میلی ثانیه وقت ببرد، پس زمان کلی تا قبل از این که timeout به اتمام برسد، برابر با ۲۰۰ میلی ثانیه (به علاوه هر چقدر که طول بکشد تا تابع setTimeout زمان قبل از آن را صفبندی کند، که معمولا یک یا دو میلی ثانیه است) خواهد بود.
در زمینه سمت سرور، اگر خیلی طول میکشد تا یک عملیات در تیک فعلی کامل شود، درخواستها نمیتواند مدیریت شوند و دریافت دادهها نمیتواند تحقق یابد؛ زیرا کد ما تا زمانی که تیک فعلی به اتمام برسد، اجرا نخواهد شد. این یعنی کدی که پر از محاسبات است، تمام تعاملات مورد انجام با سرور را کند خواهد کرد. پس پیشنهاد میشود که کارهای حساس به منابع را به چند پردازش تقسیم کنیم و آنها را از سرور اصلی فراخوانی کنیم. این کار از موقعیتهایی که در آنها مسیرهایی که به ندرت استفاده میشوند اما پربار هستند، کارایی مسیرهای دیگریی که مکررا استفاده میشوند اما خیلی پربار نیستند را کاهش میدهند، جلوگیری خواهد کرد.
سرور نمونه مقداری کد در خود دارد که حلقه رویداد را مسدود میکند، پس قدم بعدی این است که آن کد را بیابیم.
در بخش دوم که به زودی بر روی راکت قرار خواهد گرفت، با ما همراه باشید.


در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید