
در طی ۶ ماه اخیر، من در حال کار بر روی یک زبان برنامه نویسی به نام Pinecone بودهام. هنوز نمیتوان آن را «بالغ» صدا زد، اما همین حالا هم امکانات کافیای دارد که بتوان از آن استفاده کرد. مانند:
- متغیرها
- توابع
- ساختارهای تعریف شده توسط کاربر
اگر این زبان برای شما جذاب است، نگاهی به صفحه اصلی یا صفحه گیتهاب آن داشته باشید.
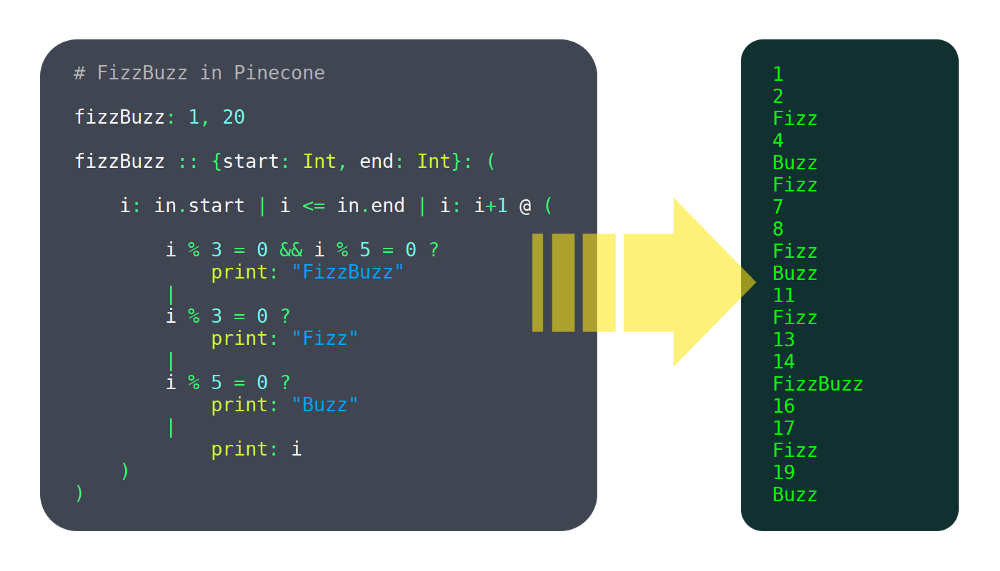
من یک متخصص نیستم. وقتی که این پروژه را شروع کردم، اصلا نمیدانستم که چه کاری دارم انجام میدهم و هنوز هم نمیدانم. من در هیچ کلاسی برای ساخت زبان شرکت نکردهام. فقط برخی آموزشهای آنلاین را خواندم، و خیلی از نصیحتهایی که دریافت کرده بودم پیروی نمیکردم.
همچنان من یک زبان کاملا جدید ساختم، و این زبان کار میکند. پس حتما کار خود را درست انجام دادهام.
در این پست، به اعماق این روند وارد خواهم شد و لولهکشی Pinecone (و زبانهای برنامه نویسی دیگر) که برای تبدیل کردن سورس کد به جادو استفاده میشوند را به شما نشان خواهم داد.
همچنین برخی از منفعتهایی که داشتهام و علت تصمیماتی که گرفتم را نیز مورد بحث قرار خواهم داد.
این آموزش، به هیچ وجه یک آموزش کامل برای نوشتن یک زبان برنامهنویسی نیست، اما اگر درباره توسعه دهی زبان کنجکاو هستید، اینجا یک نقطه شروع خوب است.
شروع کار
وقتی که من به توسعه دهندگان میگویم در حال نوشتن یک زبان هستم، جمله «اصلا نمیدانم از کجا شروع کنم» را خیلی زیاد میشنوم. اگر عکس العمل شما هم همین است، حال برخی تصمیمات اولیه که در هنگام شروع هر زبانی گرفته میشوند و قدمهایی که برداشته میشوند را بررسی خواهیم کرد.
زبان کمپایل شده (compiled)، در مقابل زبان تفسیر شده (interpreted)
دو نوع کلی از زبانها وجود دارند: کمپایل شده و تفسیر شده.
- یک کمپایلر، هر کاری که یک برنامه انجام خواهد داد را کشف میکند، آن را به «کد ماشین» (فرمتی که کامپیوتر میتواند بسیار سریع اجرا کند) تبدیل میکند و سپس آن را ذخیره میکند تا بعدا اجرا شود.
- یک تفسیر کننده، خط به خط سورس کد را میگردد و همینطور که پیش میرود، کار آن را در مییابد.
از نظر فنی هر زبانی میتواند کمپایل شده یا تفسیر شود، اما برای هر زبان خاص معمولا یکی از آنها مناسبتر است. عموما تقسیر کردن میخواهد منعطفتر باشد، در حالیکه کمپایل کردن میخواهد کارایی بیشتری داشته باشد. اما این فقط سطحی از یک موضوع بسیار پیچیده است.
کارایی به شدت برای من ارزش دارد، و من کمبود زبانهای برنامه نویسیای که هم کارایی بالایی داشته باشند و هم به سادگی گرایش داشته باشند را دیدم. پس من کمپایل شدن را برای Pinecore انتخاب کردم.
این یک تصمیم مهم بود؛ زیرا بسیاری از تصمیمات طراحی زبان تحت تاثیر آن قرار دارند. (برای مثال تایپ کردن استاتیک یک منفعت بزرگ برای زبانهای کمپایل شده است، اما برای زبانهای تفسیر شده خیلی نه)
جدا از این که Pinecone با در نظر داشتن کمپایل کردن طراحی شده بود، یک تفسیر کننده کاملا عملکردی هم دارد که برای مدتی تنها راه اجرای آن بود. چندین علت برای این مسئله وجود دارند که در ادامه توضیح خواهم داد.
انتخاب یک زبان
یک زبان برنامه نویسی، خودش یک برنامه است. از این رو شما به یک زبان برای نوشتن آن نیاز دارید. من C++ را با توجه به کارایی و مجموعه امکانات آن انتخاب کردم. همچنین من از کار کردن با C++ خیلی لذت می برم.
اگر شما در حال نوشتن یک زبان تفسیر شده هستید، این که آن را با استفاده از یک زبان کمپایل شده (مانند C، C++ یا Swift) بنویسید، کاملا عاقلانه است؛ زیرا کاراییای که در زبان تفسیر کننده شما، و تفسیر کنندهای که تفسیر کننده شما را تفسیر میکند از دست رفته است، جبران میشود.
اگر در هدف دارید که زبان خود را کمپایل کنید، یک زبان کند (مانند Python یا JavaScript) قابل قبولتر است. زمان کمپایل آن ممکن است بد باشد، اما به نظر من این مسئله آنچنان هم بد نیست.
طراحی سطح بالا
یک زبان برنامه نویسی، عموما به عنوان یک لولهکشی ساختاربندی شده است. به همین علت چندین سکو دارد. هر سکو دادهها را به روشی مشخص قالببندی کرده است. همچنین این سکو توابعی برای تغییر شکل دادهها از یک سکو به سکوی دیگر را دارد.
اولین سکو یک رشته، شامل فایل منبع ورودی به صورت کامل است. آخرین سکو، چیزی است که میتواند اجرا شود. همینطور که قدم به قدم Pinecore را بررسی میکنیم، این مسئله واضحتر خواهد شد.
Lex کردن

در اکثر زبانهای برنامه نویسی، اولین قدم Lex کردن، یا نشانه گذاری کردن است. Lex مخفف «Lexical Analysis» (تجزیه و تحلیل واژگانی) است. یک کلمه فانتزی برای تقسیم کردن مقداری متن به نشانهها. کلمه «tokenizer» (نشانه گذار) عاقلانهتر است، اما استفاده از «Lexer» جالبتر میباشد.
نشانهها
یک نشانه، یک واحد کوچک از یک زبان است. یک نشانه میتواند یک متغیر، یک نام تابع، یک عملگر یا یک عدد باشد.
وظیفه Lexer
یک Lexer باید یک رشته شامل یک فایل کلی که پر از کد است را بگیرد، و یک لیست شامل تمام نشانهها را خروجی دهد.
سکوهای آینده این لولهکشی به سورس کد اصلی ارجاع نخواهند کرد؛ پس Lexer باید تمام اطلاعاتی که مورد نیاز هستند را تولید کند. علت این قالببندی لولهکشی نسبتا سخت گیرانه، این است که Lexer بتواند عملیاتهایی مانند حذف کامنتها یا تشخیص این که یک عبارت عدد یا چیز دیگری است را انجام دهد. شما میخواهید که این منطق در داخل Lexer محفوظ بماند، تا وقتی که در حال نوشتن باقی زبان هستید، درباره این قوانین فکر نکنید، و در نتیجه بتوانید این نوع سینتکس را به کلی در یک مکان تغییر دهید.
Flex
اولین روزی که این زبان را شروع کردم، اولین چیزی که نوشتم یک Lexer ساده بود. کمی پس از آن، شروع به یادگیری درباره ابزاری کردم که ظاهرا Lexer را سادهتر کرده و باگهای آن را کاهش خواهند داد.
ابزار غالب در این زمینه، Flex است؛ یک برنامه که Lexerها را تولید میکند. شما یک فایل که یک سینتکس خاص برای توصیف قوائد زبان را دارد را به آن میدهید. این برنامه از روی آن فایل یک برنامه C را تولید میکند که یک رشته را Lex کرده، و خروجی مورد نظر را ایجاد میکند.
تصمیم من
من تصمیم گرفتم Lexerای که نوشتم را فعلا نگه دارم. در نهایت، هیچ منفعت قابل ملاحظهای در استفاده از Flex ندیدم. حداقل هیچ منفعتی برای توجیح اضافه کردن یک dependency و پیچیده کردن روند ساخت کافی نبود.
Lexer من فقط چند صد خط طول دارد، و به ندرت برای من مشکل ساز میشود. استفاده از Lexer مختص خود همچنین انعطاف بیشتری به من میدهد. مانند قابلیت اضافه کردن یک عمگر به زبان، بدون نیاز به ویرایش چندین فایل.
Parse کردن

دومین سکوی لوله کشی، parse کننده است. parse کننده لیستی از نشانهها را تبدیل به یک ساختار درختی از nodeها میکند. ساختار درختیای که برای ذخیره سازی این نوع داده استفاده میشود، با نام «Abstract Syntax Tree» یا «AST» شناخته میشود. حداقل در Pinecore، AST هیچ اطلاعاتی درباره typeها یا این که کدام شناسهها کدام هستند، ندارد.
وظایف parse کننده
Parse کننده به لیست ترتیب بندی شده نشانههایی که lexer تولید میکند، ساختار میدهد. برای توقف کردن ابهامات، parse کننده باید پرانتز و ترتیب عملیاتها را حساب کند. این که به سادگی عملگرها را parse کنیم، خیلی سخت نیست؛ اما همینطور که constructهای زبان بیشتری اضافه میشوند، parse کردن می تواند پیچیدهتر شود.
Bison
باز هم یک تصمیم دیگر حول محور یک کتابخانه جداگانه باید گرفته میشد. کتابخانه parse کردن غالب، Bison است. Bison بسیار مشابه به Flex کار میکند. شما یک فایل را در قالبی سفارشی مینویسید که اطلاعات قوائد را ذخیره میکند، و سپس Bison از آن استفاده میکند تا یک برنامه C تولید کند که عملیات parse کردن شما را انجام خواهد داد. من استفاده از Bison را انتخاب نکردم.
در بخش بعدی این مقاله، بررسی خواهیم کرد که چرا این کار به صورت سفارشی سازی شده بهتر است. همچنین به action treeها و برخی موارد دیگر هم خواهیم پرداخت. در بخش دوم که به زودی بر روی وبسایت راکت قرار خواهد گرفت، با ما همراه باشید...


در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید