
یادگیری ماشین در سالهای اخیر به یکی از مهمترین شاخههای فناوری اطلاعات و علوم داده تبدیل شده است. امروزه بسیاری از سامانههای هوشمند، از موتورهای پیشنهاددهنده و سامانههای تشخیص تقلب گرفته تا سیستمهای پردازش زبان طبیعی و بینایی ماشین، بر پایهی مدلهای یادگیری ماشین توسعه یافتهاند. در چنین شرایطی، آشنایی عملی با فرایند ساخت و ارزیابی یک مدل یادگیری ماشین، برای علاقهمندان حوزهی برنامهنویسی و تحلیل داده، ضرورتی اجتنابناپذیر محسوب میشود.
هدف اصلی یادگیری ماشین، استخراج الگوهای معنادار از دادهها و استفاده از این الگوها برای پیشبینی، طبقهبندی یا تصمیمگیری خودکار است. با وجود گستردگی مفاهیم نظری در این حوزه، بسیاری از افراد در ابتدای مسیر با این چالش مواجه میشوند که چگونه دانش تئوریک را به یک پروژهی عملی و قابل اجرا تبدیل کنند. فاصله میان مطالعهی مفاهیم پایه و پیادهسازی یک مدل واقعی، اغلب مانعی جدی برای ورود مؤثر به این حوزه به شمار میآید.
کتابخانه Scikit-learn بهعنوان یکی از پرکاربردترین ابزارهای یادگیری ماشین در زبان پایتون، امکان پیادهسازی سریع و استاندارد انواع الگوریتمهای یادگیری نظارتشده و بدوننظارت را فراهم میکند. این کتابخانه با ارائهی رابط کاربری ساده و مستندات جامع، بستری مناسب برای یادگیری اصولی و گامبهگام یادگیری ماشین ایجاد کرده است.
در این مطلب، فرایند ساخت اولین مدل یادگیری ماشین با استفاده از پایتون و کتابخانه Scikit-learn بهصورت مرحلهبهمرحله بررسی میشود. از انتخاب مسئله و آمادهسازی دادهها گرفته تا آموزش مدل، ارزیابی عملکرد و بهینهسازی آن، تمامی مراحل بهصورت کاربردی توضیح داده خواهند شد.
پیشنیازها و ابزارهای موردنیاز
پیش از ورود به فرایند ساخت مدل یادگیری ماشین، لازم است بستر فنی مناسبی برای اجرای کدها و انجام آزمایشها فراهم شود. آشنایی نسبی با ابزارها و مفاهیم پایه، موجب میشود روند یادگیری منظمتر و موثرتر پیش برود و از بروز خطاهای رایج در مراحل اولیه جلوگیری شود.
دانش و مهارتهای موردنیاز
برای بهرهگیری مناسب از محتوای این مطلب، برخورداری از سطحی پایهای از دانشهای زیر توصیه میشود:
-
آشنایی با مبانی زبان برنامهنویسی پایتون، شامل متغیرها، توابع، حلقهها و ساختارهای شرطی
-
درک مقدماتی از مفاهیم آرایه و دادههای جدولی
-
آشنایی کلی با مفاهیم آماری ساده مانند میانگین، واریانس و توزیع دادهها (در حد مقدماتی)
هرچند تسلط کامل بر این موارد الزامی نیست، اما برخورداری از این پیشزمینهها، فرایند یادگیری را تسهیل میکند.
نسخه پایتون و محیط توسعه
برای اجرای مثالهای ارائهشده در این مقاله، استفاده از نسخهی 3.8 یا بالاتر زبان پایتون پیشنهاد میشود. همچنین، بهرهگیری از یک محیط توسعهی مناسب میتواند به افزایش بهرهوری کمک کند. از جمله گزینههای رایج میتوان به موارد زیر اشاره کرد:
-
PyCharm
-
Jupyter Notebook
در میان این گزینهها، Jupyter Notebook به دلیل امکان اجرای گامبهگام کد و نمایش همزمان نتایج، برای آموزش و آزمایش مدلهای یادگیری ماشین بسیار کاربردی است.
نصب کتابخانههای موردنیاز
در این پروژه، از چند کتابخانهی پرکاربرد در حوزهی تحلیل داده و یادگیری ماشین استفاده خواهد شد. مهمترین این کتابخانهها عبارتاند از:
-
NumPy برای محاسبات عددی
-
Pandas برای مدیریت دادههای جدولی
-
Scikit-learn برای پیادهسازی الگوریتمهای یادگیری ماشین
-
Matplotlib برای ترسیم نمودارها و نمایش دادهها
برای نصب این کتابخانهها میتوان از ابزار مدیریت بستهی pip استفاده کرد:
pip install numpy pandas scikit-learn matplotlibپیشنهاد میشود پیش از نصب کتابخانهها، یک محیط مجازی (Virtual Environment) ایجاد شود تا وابستگیهای پروژه از سایر پروژهها جدا نگه داشته شوند. این کار بهویژه در پروژههای بزرگتر اهمیت بیشتری پیدا میکند.
آشنایی مقدماتی با Scikit-learn
کتابخانهی Scikit-learn یکی از استانداردترین ابزارهای یادگیری ماشین در پایتون محسوب میشود. این کتابخانه مجموعهای گسترده از الگوریتمهای طبقهبندی، رگرسیون، خوشهبندی و کاهش بُعد را در اختیار توسعهدهندگان قرار میدهد.
از ویژگیهای مهم Scikit-learn میتوان به موارد زیر اشاره کرد:
-
رابط کاربری یکپارچه برای اکثر الگوریتمها
-
مستندات دقیق و مثالهای کاربردی
-
سازگاری کامل با NumPy و Pandas
-
پشتیبانی از ابزارهای ارزیابی و بهینهسازی مدل
تعریف مسئله و انتخاب دیتاست
پیش از آغاز فرایند پیادهسازی مدل یادگیری ماشین، لازم است مسئله موردنظر بهصورت دقیق تعریف شود و دادههای مناسبی برای آموزش و ارزیابی مدل انتخاب گردند. بدون تعریف روشن مسئله و شناخت کافی از دادهها، حتی پیشرفتهترین الگوریتمها نیز قادر به ارائهی نتایج قابل اعتماد نخواهند بود.
یادگیری ماشین، در ماهیت خود، ابزاری برای حل مسئله است، نه مجموعهای از دستورات از پیش آماده. ازاینرو، نخستین گام در هر پروژهی موفق، تبدیل یک نیاز واقعی به یک مسئلهی قابل مدلسازی است.
تعیین نوع مسئله
مسائل یادگیری ماشین بهطور کلی به چند دستهی اصلی تقسیم میشوند که در این مطلب بر یکی از رایجترین آنها تمرکز میشود:
-
یادگیری نظارتشده (Supervised Learning): در این نوع مسائل، دادهها دارای برچسب یا مقدار هدف هستند و مدل تلاش میکند رابطهی میان ورودیها و خروجی را بیاموزد.
-
یادگیری بدون نظارت (Unsupervised Learning): در این حالت، دادهها فاقد برچسب هستند و هدف، کشف الگوها یا ساختارهای پنهان در دادهها است.
در این آموزش، تمرکز اصلی بر یادگیری نظارتشده و بهطور مشخص بر مسئله طبقهبندی (Classification) خواهد بود. در مسائل طبقهبندی، هدف آن است که هر نمونهی ورودی به یکی از چند گروه مشخص اختصاص داده شود.
معرفی دیتاست مورد استفاده
برای پیادهسازی عملی مفاهیم مطرحشده، از دیتاست «گلهای زنبق» (Iris Dataset) استفاده میشود. این مجموعهداده یکی از شناختهشدهترین دیتاستهای آموزشی در حوزهی یادگیری ماشین است و به دلیل سادگی ساختار، برای شروع بسیار مناسب است.
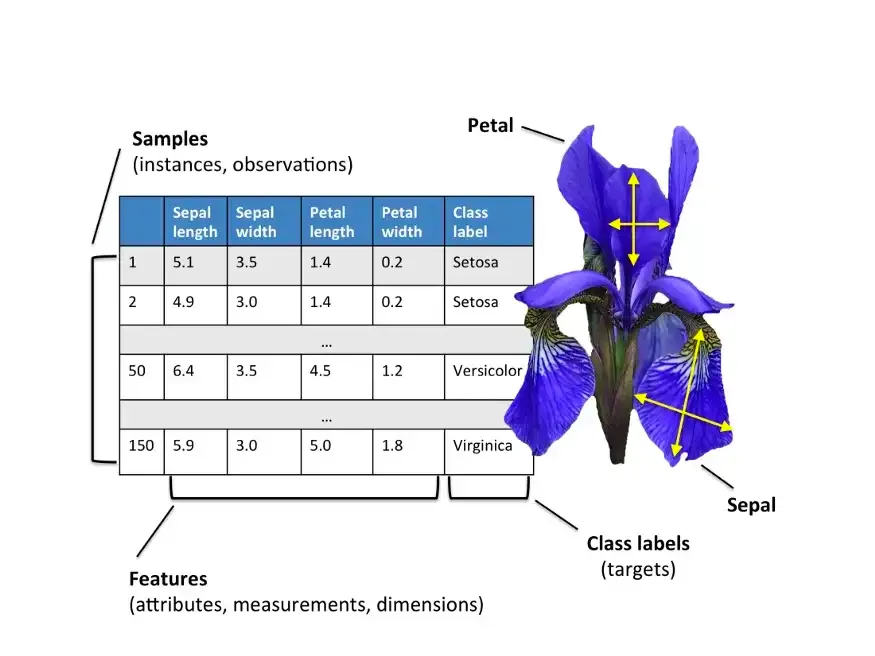
دیتاست Iris شامل اطلاعات مربوط به ۱۵۰ نمونهی گل زنبق از سه گونهی مختلف است. برای هر نمونه، چهار ویژگی عددی اندازهگیری شده است:
-
طول کاسبرگ (Sepal Length)
-
عرض کاسبرگ (Sepal Width)
-
طول گلبرگ (Petal Length)
-
عرض گلبرگ (Petal Width)
هدف مدل، تشخیص گونهی گل بر اساس این چهار ویژگی است.
سه کلاس موجود در این دیتاست عبارتاند از:
-
Setosa
-
Versicolor
-
Virginica
این دیتاست بهصورت پیشفرض در کتابخانهی Scikit-learn در دسترس است و نیازی به دانلود جداگانه ندارد.
بارگذاری دیتاست در محیط پایتون
کتابخانهی Scikit-learn امکان بارگذاری مستقیم دیتاست Iris را فراهم میکند. برای دریافت این دادهها میتوان از کد زیر استفاده کرد:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.targetدر این کد:
-
متغیر
Xشامل ویژگیهای ورودی است. -
متغیر
yشامل برچسبهای مربوط به هر نمونه است.
ساختار دادهها بهگونهای طراحی شده است که مستقیما قابلیت استفاده در الگوریتمهای یادگیری ماشین را داشته باشند.
اهمیت انتخاب دیتاست مناسب
انتخاب دیتاست مناسب، نقش تعیینکنندهای در کیفیت نتایج نهایی دارد. یک دیتاست مناسب برای آموزش اولیه باید دارای ویژگیهای زیر باشد:
-
حجم متعادل (نه بسیار کوچک و نه بیش از حد بزرگ)
-
ساختار شفاف و قابل تحلیل
-
حداقل میزان دادههای ناقص یا نامعتبر
-
ارتباط منطقی میان ویژگیها و خروجی موردنظر
دیتاست Iris با برخورداری از این ویژگیها، بستری مناسب برای درک مفاهیم پایهی یادگیری ماشین فراهم میکند و امکان تمرکز بر فرایند مدلسازی را بدون پیچیدگیهای اضافی مهیا میسازد.
بررسی اولیه و تحلیل دادهها
پس از تعریف مسئله و انتخاب دیتاست مناسب، گام بعدی بررسی ساختار دادهها و تحلیل اولیهی آنها است. این مرحله که معمولا با عنوان «تحلیل اکتشافی دادهها» (Exploratory Data Analysis یا EDA) شناخته میشود، نقش مهمی در درک ویژگیهای داده و شناسایی مشکلات احتمالی دارد.
نادیدهگرفتن این مرحله میتواند منجر به استفاده از دادههای نامناسب، برداشتهای نادرست و در نهایت تولید مدلهای کمدقت شود. از اینرو، پیش از ورود به مرحلهی آموزش مدل، لازم است تصویری روشن از وضعیت دادهها به دست آید.
تبدیل دادهها به ساختار DataFrame
برای سهولت در تحلیل دادهها، ابتدا دادههای بارگذاریشده را به قالب DataFrame در کتابخانهی Pandas تبدیل میکنیم. این قالب امکان مشاهده، فیلتر و پردازش آسان دادهها را فراهم میکند.
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.targetدر این مرحله، ویژگیهای ورودی و ستون هدف در یک جدول واحد قرار میگیرند که تحلیل آن را سادهتر میسازد.
مشاهدهی ساختار کلی دادهها
برای آشنایی اولیه با دادهها، بررسی چند سطر ابتدایی و انتهایی جدول ضروری است:
df.head()
df.tail()این دستورات نمایی کلی از نحوهی ذخیرهسازی دادهها، نوع مقادیر و نام ستونها ارائه میدهند.
همچنین، برای اطلاع از تعداد سطرها، ستونها و نوع دادهها میتوان از دستور زیر استفاده کرد:
df.info()خروجی این دستور اطلاعاتی دربارهی تعداد نمونهها، نوع متغیرها و میزان دادههای ناقص ارائه میدهد.
بررسی آمار توصیفی دادهها
برای درک بهتر توزیع مقادیر عددی، از آمار توصیفی استفاده میشود:
df.describe()این دستور شاخصهایی مانند میانگین، انحراف معیار، کمینه، بیشینه و چارکها را نمایش میدهد. تحلیل این مقادیر به شناسایی دادههای غیرعادی یا پراکندگی نامتوازن کمک میکند.
بررسی دادههای گمشده
وجود دادههای ناقص یکی از مشکلات رایج در پروژههای واقعی یادگیری ماشین است. هرچند دیتاست Iris فاقد دادههای گمشده است، بررسی این موضوع بهعنوان یک اصل مهم توصیه میشود:
df.isnull().sum()در پروژههای واقعی، مشاهدهی مقادیر غیرصفر در این بخش، نیازمند انجام مراحل پاکسازی یا جایگزینی دادهها خواهد بود.
تحلیل توزیع کلاسها
در مسائل طبقهبندی، بررسی تعداد نمونههای هر کلاس اهمیت ویژهای دارد. عدم توازن میان کلاسها میتواند موجب بروز سوگیری در مدل شود.
برای بررسی توزیع برچسبها میتوان از کد زیر استفاده کرد:
df['target'].value_counts()در دیتاست Iris، توزیع نمونهها میان سه کلاس تقریبا متعادل است که شرایط مناسبی برای آموزش مدل فراهم میکند.
نمایش بصری دادهها
تصویرسازی دادهها نقش مهمی در کشف الگوهای پنهان ایفا میکند. با استفاده از نمودارهای ساده میتوان ارتباط میان ویژگیها را بررسی کرد.
نمونهای از ترسیم نمودار پراکندگی:
import matplotlib.pyplot as plt
plt.scatter(df['sepal length (cm)'], df['petal length (cm)'])
plt.xlabel('Sepal Length')
plt.ylabel('Petal Length')
plt.show()این نمودار امکان مشاهدهی رابطهی میان طول کاسبرگ و طول گلبرگ را فراهم میکند و میتواند نشانههایی از قابلیت تفکیک کلاسها ارائه دهد.
نقش تحلیل اولیه در کیفیت مدل
تحلیل اولیهی دادهها، زمینهساز تصمیمگیریهای مهم در مراحل بعدی است. نتایج این بررسیها میتوانند بر موارد زیر تاثیر مستقیم داشته باشند:
-
انتخاب نوع الگوریتم مناسب
-
نیاز به نرمالسازی یا مقیاسبندی دادهها
-
شناسایی ویژگیهای کماهمیت
-
تشخیص دادههای پرت یا نامعتبر
با انجام دقیق این مرحله، احتمال بروز خطاهای ساختاری در مراحل بعدی کاهش مییابد و مسیر توسعهی مدل بهصورت منطقی و قابل پیشبینی پیش خواهد رفت.
آمادهسازی و پیشپردازش دادهها
پس از بررسی اولیه و تحلیل ساختار دادهها، نوبت به مرحلهی آمادهسازی و پیشپردازش دادهها میرسد. این مرحله یکی از مهمترین بخشهای هر پروژهی یادگیری ماشین محسوب میشود، زیرا کیفیت دادههای ورودی تاثیر مستقیمی بر عملکرد نهایی مدل دارد. در بسیاری از پروژههای واقعی، بخش عمدهای از زمان توسعه صرف همین مرحله میشود.
دادههای خام، حتی در صورت کامل بودن، معمولاا بهصورت مستقیم برای آموزش مدل مناسب نیستند. تفاوت مقیاس ویژگیها، وجود مقادیر نامعتبر، یا ساختار نامناسب دادهها میتواند موجب کاهش دقت و پایداری مدل شود. ازاینرو، پیشپردازش صحیح، شرط لازم برای دستیابی به نتایج قابل اعتماد است.
تفکیک ویژگیها و متغیر هدف
در نخستین گام، باید ویژگیهای ورودی (Features) و متغیر هدف (Target) از یکدیگر جدا شوند. این تفکیک، ساختار اصلی دادههای آموزشی را تشکیل میدهد.
X = df.drop('target', axis=1)
y = df['target']در این کد، تمامی ستونها بهجز ستون هدف بهعنوان ورودی مدل در نظر گرفته شدهاند.
تقسیم دادهها به مجموعه آموزش و آزمون
برای ارزیابی منصفانهی عملکرد مدل، دادهها به دو بخش مجزا تقسیم میشوند:
-
مجموعهی آموزش (Training Set) برای یادگیری الگوها
-
مجموعهی آزمون (Test Set) برای سنجش عملکرد نهایی
این کار مانع از ارزیابی مدل بر اساس دادههایی میشود که قبلاً آنها را دیده است.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)در این مثال، ۲۰ درصد دادهها برای آزمون در نظر گرفته شدهاند.
مقیاسبندی ویژگیها (Feature Scaling)
در بسیاری از الگوریتمهای یادگیری ماشین، تفاوت مقیاس میان ویژگیها میتواند بر روند یادگیری تاثیر منفی بگذارد. بهعنوان مثال، اگر یک ویژگی در بازهی ۰ تا ۱ و ویژگی دیگر در بازهی ۰ تا ۱۰۰۰ باشد، الگوریتم ممکن است بهصورت نامتوازن به ویژگی دوم توجه کند.
برای رفع این مشکل، از روشهای مقیاسبندی استفاده میشود. یکی از رایجترین روشها، استانداردسازی (Standardization) است:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)در این روش، ویژگیها بهگونهای تبدیل میشوند که دارای میانگین صفر و انحراف معیار یک باشند.
نکتهی مهم آن است که عملیات fit تنها روی دادههای آموزش انجام میشود تا از نشت اطلاعات (Data Leakage) جلوگیری شود.
مدیریت دادههای گمشده و نامعتبر
در پروژههای واقعی، معمولا دادهها دارای مقادیر گمشده یا نادرست هستند. هرچند دیتاست Iris فاقد چنین مشکلی است، اما آشنایی با روشهای رایج ضروری است.
یکی از روشهای متداول، جایگزینی مقادیر گمشده با میانگین یا میانه است:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)انتخاب روش مناسب جایگزینی، به ماهیت داده و نوع مسئله بستگی دارد.
استفاده از Pipeline برای مدیریت مراحل پیشپردازش
برای سازماندهی بهتر مراحل پردازش و جلوگیری از خطاهای ساختاری، میتوان از ابزار Pipeline در Scikit-learn استفاده کرد. این ابزار امکان ترکیب چند مرحلهی پردازشی و مدلسازی را در قالب یک جریان واحد فراهم میکند.
نمونهای ساده:
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])با استفاده از Pipeline، کلیهی مراحل پیشپردازش و آموزش بهصورت یکپارچه اجرا میشوند که این امر خوانایی و قابلیت نگهداری کد را افزایش میدهد.
تاثیر پیشپردازش بر کیفیت مدل
پیشپردازش مناسب دادهها میتواند منجر به بهبود قابل توجه عملکرد مدل شود. مهمترین نتایج این مرحله عبارتاند از:
-
افزایش سرعت همگرایی الگوریتم
-
کاهش خطاهای عددی
-
جلوگیری از سوگیری مدل
-
بهبود قابلیت تعمیم به دادههای جدید
در بسیاری از موارد، بهینهسازی مرحلهی پیشپردازش تاثیر بیشتری بر دقت مدل دارد تا تغییر الگوریتم مورد استفاده. ازاینرو، توجه جدی به این بخش، یکی از نشانههای رویکرد حرفهای در پروژههای یادگیری ماشین است.
ساخت و آموزش مدل اولیه
پس از آمادهسازی و پیشپردازش دادهها، میتوان وارد مرحلهی ساخت و آموزش مدل یادگیری ماشین شد. در این مرحله، یک الگوریتم مناسب انتخاب میشود و با استفاده از دادههای آموزشی، فرایند یادگیری الگوها آغاز میگردد. هدف اصلی در این بخش، ایجاد یک مدل پایه (Baseline Model) است که بتواند عملکرد اولیهی مسئله را مشخص کند.
مدل پایه، سادهترین نسخهی قابل قبول از یک راهحل محسوب میشود و معیار مناسبی برای مقایسه با نسخههای بهینهشدهی بعدی فراهم میکند. بدون ایجاد چنین مدلی، ارزیابی میزان پیشرفت در مراحل بعدی دشوار خواهد بود.
انتخاب الگوریتم مناسب
برای مسائل طبقهبندی، الگوریتمهای متعددی در Scikit-learn در دسترس هستند. از میان آنها، «رگرسیون لجستیک» (Logistic Regression) یکی از گزینههای مناسب برای شروع محسوب میشود، زیرا:
-
پیادهسازی سادهای دارد
-
سرعت آموزش بالایی ارائه میدهد
-
رفتار آن قابل تفسیر است
-
برای مسائل با دادهی عددی عملکرد قابل قبولی دارد
به همین دلیل، در این آموزش از الگوریتم Logistic Regression بهعنوان مدل اولیه استفاده میشود.
ایجاد نمونهی مدل
ابتدا یک نمونه از مدل موردنظر ایجاد میکنیم:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000)
پارامتر max_iter تعداد تکرارهای مجاز برای همگرایی الگوریتم را مشخص میکند و افزایش آن از بروز خطای عدم همگرایی جلوگیری میکند.
آموزش مدل با دادههای آموزشی
پس از ایجاد نمونهی مدل، باید آن را با استفاده از دادههای آموزش، تعلیم داد. این کار از طریق متد fit انجام میشود:
model.fit(X_train_scaled, y_train)
در این مرحله، الگوریتم تلاش میکند الگوهای موجود در دادهها را شناسایی کرده و پارامترهای داخلی خود را بهینهسازی کند.
فرایند آموزش معمولاً بهصورت خودکار انجام میشود و بسته به حجم دادهها و نوع الگوریتم، ممکن است از چند میلیثانیه تا چند دقیقه زمان ببرد.
پیشبینی بر روی دادههای آزمون
پس از آموزش مدل، میتوان از آن برای پیشبینی برچسب نمونههای جدید استفاده کرد. در این مرحله، دادههای آزمون که در فرایند آموزش دخالت نداشتهاند، مورد استفاده قرار میگیرند:
y_pred = model.predict(X_test_scaled)
متغیر y_pred شامل برچسبهای پیشبینیشده توسط مدل است.
این خروجی، مبنای اصلی ارزیابی عملکرد مدل در مرحلهی بعد خواهد بود.
تفسیر عملکرد مدل پایه
مدل اولیه معمولاً بهترین مدل ممکن نیست و نباید از آن انتظار دقت بسیار بالا داشت. هدف اصلی از ساخت این مدل، دستیابی به یک نقطهی مرجع است که بتوان به کمک آن میزان بهبود در مراحل بعدی را اندازهگیری کرد.
در این مرحله، تمرکز بر موارد زیر اهمیت دارد:
-
بررسی امکان یادگیری الگوهای پایه
-
اطمینان از صحت پیادهسازی مراحل قبلی
-
شناسایی مشکلات ساختاری احتمالی
-
ایجاد مبنای مقایسه برای بهینهسازی آینده
اگر مدل پایه عملکرد بسیار ضعیفی داشته باشد، معمولاً نشانهای از وجود مشکل در دادهها، پیشپردازش یا تعریف مسئله است و باید به مراحل قبل بازگشت و آنها را بازبینی کرد.
نقش مدل پایه در توسعهی تدریجی سیستم
رویکرد حرفهای در پروژههای یادگیری ماشین مبتنی بر توسعهی تدریجی است. ابتدا یک مدل ساده ساخته میشود، سپس بهمرور با بهبود دادهها، تنظیم پارامترها و انتخاب الگوریتمهای پیشرفتهتر، عملکرد سیستم ارتقا مییابد.
ساخت مدل اولیه، نخستین گام در این مسیر است و پایهی تمام بهبودهای بعدی بر آن استوار خواهد بود.
ارزیابی عملکرد مدل
پس از آموزش مدل و انجام پیشبینی بر روی دادههای آزمون، لازم است عملکرد آن بهصورت دقیق و نظاممند ارزیابی شود. ارزیابی صحیح، یکی از اساسیترین مراحل در پروژههای یادگیری ماشین است، زیرا بدون سنجش علمی نتایج، نمیتوان دربارهی کیفیت مدل یا میزان قابلیت اعتماد آن قضاوت معتبری ارائه داد.
اتکا به یک معیار ساده و سطحی، ممکن است تصویری نادرست از عملکرد واقعی مدل ایجاد کند. ازاینرو، در این بخش با مهمترین روشهای ارزیابی مدلهای طبقهبندی آشنا میشویم.
محاسبهی دقت (Accuracy)
سادهترین معیار ارزیابی در مسائل طبقهبندی، «دقت» یا Accuracy است. این شاخص، نسبت پیشبینیهای صحیح به کل نمونهها را نشان میدهد.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)هرچند دقت معیار مفیدی است، اما در بسیاری از مسائل بهتنهایی کافی نیست. در صورت نامتوازن بودن کلاسها، ممکن است مقدار Accuracy بالا باشد، در حالی که مدل عملکرد ضعیفی در تشخیص کلاسهای مهم دارد.
ماتریس درهمریختگی (Confusion Matrix)
برای درک دقیقتر نحوهی پیشبینی مدل، از ماتریس درهمریختگی استفاده میشود. این ماتریس نشان میدهد که هر کلاس تا چه اندازه بهدرستی یا نادرستی پیشبینی شده است.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)در این ماتریس:
-
سطرها نشاندهندهی مقادیر واقعی
-
ستونها نشاندهندهی مقادیر پیشبینیشده
هستند. بررسی این جدول امکان شناسایی الگوهای خطا را فراهم میکند.
معیارهای Precision ،Recall و F1-Score
برای ارزیابی جامعتر مدل، از سه معیار مکمل استفاده میشود:
-
Precision (دقت مثبت): میزان صحت پیشبینیهای مثبت
-
Recall (بازخوانی): میزان شناسایی صحیح نمونههای مثبت
-
F1-Score: میانگین موزون Precision و Recall
این معیارها بهویژه در مسائل حساس، مانند تشخیص بیماری یا تقلب، اهمیت بالایی دارند.
برای محاسبهی این شاخصها میتوان از گزارش طبقهبندی استفاده کرد:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))این گزارش، تصویری جامع از عملکرد مدل برای هر کلاس ارائه میدهد.
بررسی بیشبرازش و کمبرازش
یکی از چالشهای مهم در یادگیری ماشین، مسئلهی بیشبرازش (Overfitting) و کمبرازش (Underfitting) است.
-
کمبرازش: مدل قادر به یادگیری الگوهای اصلی داده نیست.
-
بیشبرازش: مدل بیشازحد به دادههای آموزش وابسته میشود و در دادههای جدید عملکرد ضعیفی دارد.
برای بررسی این موضوع، میتوان عملکرد مدل روی دادههای آموزش و آزمون را مقایسه کرد:
train_score = model.score(X_train_scaled, y_train)
test_score = model.score(X_test_scaled, y_test)
print("Train Score:", train_score)
print("Test Score:", test_score)تفاوت زیاد میان این دو مقدار، میتواند نشانهای از بیشبرازش باشد.
بهینهسازی و تنظیم پارامترهای مدل
پس از ارزیابی عملکرد مدل پایه، معمولا مشخص میشود که اگرچه مدل قادر به یادگیری الگوهای اصلی دادهها است، اما هنوز فاصلهی قابل توجهی با عملکرد بهینه دارد. در این مرحله، تمرکز اصلی بر بهبود کیفیت مدل از طریق تنظیم پارامترها و استفاده از روشهای اعتبارسنجی پیشرفته قرار میگیرد.
بسیاری از الگوریتمهای یادگیری ماشین دارای پارامترهایی هستند که رفتار مدل را کنترل میکنند. انتخاب مناسب این پارامترها، میتواند تأثیر مستقیمی بر دقت، پایداری و قابلیت تعمیم مدل داشته باشد.
تفاوت پارامتر و ابرپارامتر
در مدلهای یادگیری ماشین، دو نوع متغیر اصلی وجود دارد:
-
پارامترها (Parameters): مقادیری که در فرایند آموزش توسط مدل یاد گرفته میشوند.
-
ابرپارامترها (Hyperparameters): مقادیری که پیش از آموزش تعیین میشوند و ساختار یادگیری مدل را مشخص میکنند.
بهعنوان مثال، در رگرسیون لجستیک، پارامترهایی مانند ضرایب ویژگیها در طول آموزش تعیین میشوند، در حالی که پارامترهایی مانند نوع منظمسازی یا مقدار C از نوع ابرپارامتر محسوب میشوند.
اهمیت تنظیم ابرپارامترها
استفاده از مقادیر پیشفرض کتابخانهها، اگرچه برای شروع مناسب است، اما معمولا بهترین عملکرد ممکن را فراهم نمیکند. تنظیم دقیق ابرپارامترها میتواند منجر به:
-
کاهش بیشبرازش
-
افزایش دقت پیشبینی
-
بهبود پایداری مدل
-
افزایش قابلیت تعمیم
شود.
ازاینرو، این مرحله نقش کلیدی در تبدیل یک مدل معمولی به یک مدل قابل اتکا ایفا میکند.
اعتبارسنجی متقابل (Cross-Validation)
برای ارزیابی پایدارتر مدل، از روش اعتبارسنجی متقابل استفاده میشود. در این روش، دادهها به چند بخش تقسیم شده و مدل چندین بار آموزش و ارزیابی میشود.
یکی از رایجترین روشها، اعتبارسنجی k-بخشی (k-Fold) است.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train_scaled, y_train, cv=5)
print("Cross-validation scores:", scores)
print("Mean score:", scores.mean())این روش، وابستگی نتایج به یک تقسیمبندی خاص از دادهها را کاهش میدهد.
استفاده از GridSearchCV برای تنظیم پارامترها
برای جستوجوی سیستماتیک بهترین ترکیب ابرپارامترها، میتوان از ابزار GridSearchCV استفاده کرد. این ابزار تمامی ترکیبهای ممکن از پارامترهای مشخصشده را بررسی میکند.
نمونهای از تنظیم پارامترهای رگرسیون لجستیک:
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.01, 0.1, 1, 10, 100],
'solver': ['lbfgs', 'liblinear']
}
grid = GridSearchCV(
LogisticRegression(max_iter=1000),
param_grid,
cv=5,
scoring='accuracy'
)
grid.fit(X_train_scaled, y_train)پس از اجرای این کد، بهترین ترکیب پارامترها بهصورت زیر قابل دسترسی است:
print("Best parameters:", grid.best_params_)
print("Best score:", grid.best_score_)ترکیب Pipeline و GridSearch
برای مدیریت همزمان پیشپردازش و تنظیم پارامترها، میتوان Pipeline را با GridSearch ترکیب کرد. این روش از نشت اطلاعات جلوگیری کرده و ساختار پروژه را حرفهایتر میکند.
نمونهی ترکیبی:
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression(max_iter=1000))
])
param_grid = {
'model__C': [0.1, 1, 10],
'model__solver': ['lbfgs', 'liblinear']
}
grid = GridSearchCV(pipeline, param_grid, cv=5)
grid.fit(X_train, y_train)در این ساختار، تمام مراحل بهصورت یکپارچه اعتبارسنجی میشوند.
تحلیل نتایج بهینهسازی
پس از پایان فرایند جستوجو، لازم است نتایج بهصورت تحلیلی بررسی شوند. صرفاً انتخاب بهترین عدد کافی نیست، بلکه باید به موارد زیر توجه شود:
-
پایداری نتایج در folds مختلف
-
تفاوت عملکرد میان ترکیبها
-
هزینهی محاسباتی
-
میزان بهبود نسبت به مدل پایه
گاهی یک بهبود جزئی، هزینهی محاسباتی بسیار بالایی دارد که از نظر عملی توجیهپذیر نیست.
جایگاه بهینهسازی در فرایند توسعه
بهینهسازی، مرحلهی نهایی نیست، بلکه بخشی از یک چرخهی مستمر بهبود محسوب میشود. پس از تنظیم پارامترها، ممکن است نیاز به بازنگری در دادهها، ویژگیها یا حتی انتخاب الگوریتم وجود داشته باشد.
ذخیرهسازی و استفاده از مدل آموزشدیده
پس از ساخت، آموزش و بهینهسازی مدل، مرحلهی بعدی ذخیرهسازی آن برای استفادههای آینده و پیادهسازی در محیطهای واقعی است. این مرحله بهویژه در پروژههای بزرگ و عملیاتی اهمیت پیدا میکند، زیرا مدلهای آموزشدیده میتوانند بدون نیاز به آموزش مجدد، بارها و بارها مورد استفاده قرار گیرند.
ذخیرهسازی مدل
در پایتون، برای ذخیرهسازی مدلهای آموزشدیده معمولاً از کتابخانهی joblib یا pickle استفاده میشود. این ابزارها امکان نگهداری پارامترهای یاد گرفتهشده توسط مدل و مراحل پیشپردازش مرتبط را فراهم میکنند.
نمونهی ذخیره مدل با استفاده از joblib:
import joblib
# ذخیره مدل
joblib.dump(grid.best_estimator_, 'iris_model.pkl')در این مثال، مدل آموزشدیده و بهینهشده در فایل iris_model.pkl ذخیره میشود و در هر زمان قابل بارگذاری و استفاده است.
بارگذاری مدل
برای استفاده مجدد از مدل ذخیرهشده، کافی است آن را بارگذاری کرده و دادههای جدید را به آن اعمال کنیم:
# بارگذاری مدل
loaded_model = joblib.load('iris_model.pkl')
# پیشبینی با دادههای جدید
y_new_pred = loaded_model.predict(X_test_scaled)بارگذاری مدل باعث صرفهجویی در زمان و منابع محاسباتی میشود، زیرا دیگر نیازی به آموزش مجدد مدل وجود ندارد.
کاربردهای عملی
مدل ذخیرهشده را میتوان در محیطهای مختلف به کار برد:
-
پیادهسازی در وبسرویسها یا API: مدل میتواند در یک سرویس وب تعبیه شده و به درخواستهای کاربران پاسخ دهد.
-
استفاده در پروژههای تحلیلی: تحلیلهای پیشرفته و گزارشدهی با دادههای جدید بدون نیاز به آموزش مجدد.
-
توسعهی مدلهای ترکیبی: مدل اولیه بهعنوان بخشی از یک سیستم بزرگتر یا در ترکیب با مدلهای دیگر مورد استفاده قرار گیرد.
نکات حرفهای
-
همواره مسیر و نام فایل مدل را مشخص و مستند کنید تا در پروژههای بزرگ امکان مدیریت مدلها آسان باشد.
-
در صورت استفاده از دادههای واقعی و حساس، مراقبت از امنیت فایل مدل ضروری است، زیرا مدل میتواند اطلاعاتی از دادههای آموزش حفظ کند.
-
در پروژههای عملی، ذخیرهسازی Pipeline کامل شامل پیشپردازش و مدل، به جای ذخیرهی تنها مدل، توصیه میشود تا از خطاهای ناشی از تفاوت پردازش دادههای جدید جلوگیری شود.
جمعبندی
ساخت اولین مدل یادگیری ماشین با پایتون و Scikit-learn، نقطهی شروعی عملی برای ورود به دنیای هوش مصنوعی است. در این مقاله، مراحل اصلی شامل تعریف مسئله، پیشپردازش دادهها، آموزش مدل، ارزیابی و بهینهسازی پارامترها و ذخیرهسازی مدل تشریح شد.
تمرکز بر تحلیل دادهها، ساخت مدل پایه و ارزیابی منظم، پایهی موفقیت در پروژههای یادگیری ماشین است. پس از این مرحله، مسیر یادگیری میتواند شامل الگوریتمهای پیشرفتهتر، کار با دادههای واقعی، بهبود مهارتهای بصریسازی و پیادهسازی پروژههای عملی باشد.
این مراحل، چارچوبی ساده اما قابل توسعه فراهم میکنند تا علاقهمندان، گامهای بعدی در یادگیری ماشین را با دیدی روشن و عملی بردارند.

در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید