
(SQL مخفف (Structured Query Language یک زبان قدرتمند برای برخورد با دادههای پایگاه داده های رابطهای است. اما ممکن است برای افرادی که آگاهی کافی در این باره ندارند، دلهرهآور به نظر برسد.
"دستورالعمل" هایی که امروز میخواهم با شما به اشتراک بگذارم، چند نمونه اصلی از یک بانکاطلاعاتی ساده است.اما الگویی که دراینجا یادخواهید گرفت میتواند به شما در نوشتن کوئریهای دقیقتر کمک میکند.
یک نکته درباره سینتکس: بیشتر کوئریهای زیر به سبک PostgreSQL که از خط فرمان psql استفاده میکند، نوشته شدهاند. موتورهای مختلف SQL میتوانند از دستوراتی که کمی متفاوت تر است استفاده کنند.
اکثر کوئریهای زیر باید در اکثر موتورها بدون هیچگونه دردسری کار کنند، اگرچه ممکن است برخی از موتورها یا ابزارهای GUI نیاز به حذف علامتهای کوتیشن(نقل قول) در اطراف نام جدول و ستونها داشته باشند.
ظرف ۱: تمام کاربرانی که در یک بازه زمانی خاص ایجاد شدهاند را برگردانید.
مواد لازم:
SELECT
FROM
WHERE
AND
Method
متد
SELECT *
FROM "Users"
WHERE "created_at" > "2020-01-01"
AND "created_at" < "2020-02-01";این ظرف یک عنصراصلی تطبیقپذیر است. در اینجا ما کاربرانی را برمیگردانیم که دو شرط خاص را با زنجیرکردن (chaining) شرط WHERE با یک AND statement را رعایت میکنند. این را میتوانیم با AND statements بیشتر گسترش دهیم.
درحالی که مثال اینجا برای یک محدوده خاص تاریخ است، اکثر کوئریها برای فیلتر کردن دادههای مفید نیاز به نوعی شرط دارند.
ظرف ۲: تمام نظرات مربوط به یک کتاب را پیدا کنید، از جمله کاربری که این نظر را ساخته است.
(جدید) مواد لازم
- JOIN
متد
SELECT "Comments"."comment", "Users"."username"
FROM "Comments"
JOIN "Users"
ON "Comments"."userId" = "Users"."id"
WHERE "Comments"."bookId" = 1;این کوئری ساختار جدول زیر را فرض میکند:
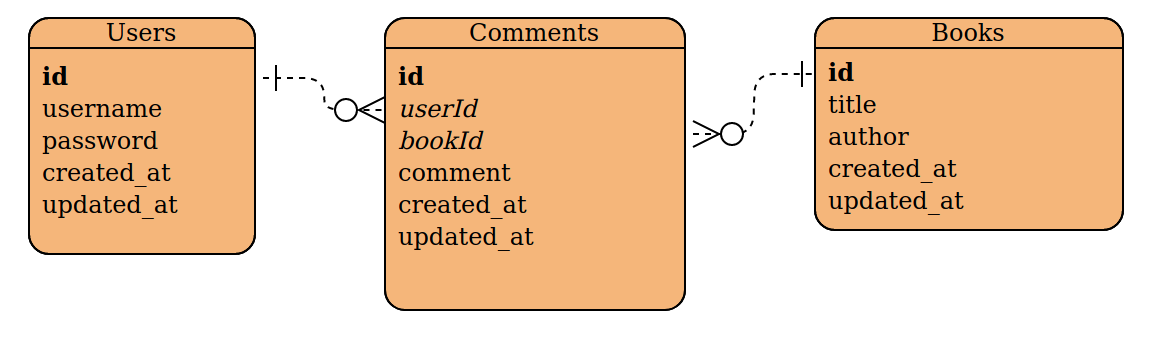
ERD کاربرانی را نشان میدهد که میتوانند نظرات بسیاری داشته باشند، و همچنین کتابهایی که میتوانند نظرات بسیاری داشته باشند.
یکی از مواردی که میتواند موجب سردرگمی تازهکارها در SQL شود،استفاده از JSON ها برای یافتن داده از جداول مرتبط است.
ERD (Entity Relationship Diagram) یا به عبارت دیگر نموداری که رابطه موجودیتها را نشان میدهد، دربالا سه جدول کاربران، کتابها و نظرات و روابط بین آنها را نمایش میدهد.
در هر جدول یک id وجود دارد که در نمودار به صورت پررنگ نشان داده میشودکه کلید اصلی (primary key) برای جدول است. این کلید اصلی همیشه یک مقدار منحصر به فرد است و برای تعریف رکوردها در جداول جداگانه استفاده میشود.
نام ستونهای userId و bookId که italic شده جدول نظرات کلیدهای خارجی هستند، به این معنی که آنها کلید اصلی جدولهای دیگر هستند و در اینجا برای مرجع آن جداول استفاده شده است.
اتصالات موجود در ERD بالا ماهیت روابط بین ۳ جدول را نشان میدهد.
انتهای یک نقطه در اتصال، به معنای "one" است و انتهای تقسیم روی یک کانکتور به معنای"many" است، بنابراین جدول کاربر با جدول نظرات رابطه " یک به چند" دارد.
به عنوان مثال یک کاربر میتواند نظرات بسیاری داشته باشد، اما یک نظر فقط میتواند متعلق به یک کاربر واحد باشد. کتابها و نظرات در نمودار بالا یکسان هستند.
کوئری SQL باید بر اساس آنچه که میدانیم باشد.ما فقط ستونهای نامگذاری شده را برمیگردانیم، یعنی ستون نظرات از جدول نظرات و نامکاربری از جدول کاربران که رابطه دارد(بر اساس کلید خارجی ارجاع شده). درمثال بالا، جستجوی یک کتاب را محدود میکنیم، این هم دوباره بر اساس کلید خارجی در جدول نظرات است.
ظرف ۳: تعداد نظرات اضافه شده توسط هر کاربر را بشمارید
(جدید) مواد لازم
COUNT
AS
GROUP BY
متد
SELECT "Users"."username", COUNT("Comments"."id") AS "CommentCount"
FROM "Comments"
JOIN "Users"
ON "Comments"."userId" = "Users"."id"
GROUP BY "Users"."id";این جستجوی کوچک چند نکته جالب دارد. و سادهترین برای درک کردن AS statement است. این به ما اجازه میدهد تا به صورت دلخواه و موقت، ستونها را در دادههایی که برگرداندیم تغییر دهیم. در اینجا ستون مشتق شده را تغییر میدهیم، اما این هنگامی که چندین id ستون داریم هم مقید است، زیرا میتواند مواردی مثل userId یا commentId و … را تغییر دهید.
COUNT statement یک فانکشن SQL است که همانطور که انتظار دارید همه چیز را محاسبه میکند. در اینجا ما تعداد نظرات مرتبط با یک کاربر را شمارش میکنیم. چگونه کار میکند؟ خب GROUP BY عنصر مهم و نهایی است.
بیایید به طور خلاصه یک سؤال کمی متفاوت را تصور کنیم:
SELECT "Users"."username", "Comments"."comment"
FROM "Comments"
JOIN "Users"
ON "Comments"."userId" = "Users"."id";توجه! بدون شمارش و گروهبندی باشد. ما فقط هر نظر را میخواهیم و اینکه چه کسی آن را بیان کرده است.
ممکن است خروجی چیزی شبیه به این باشد:

حال تصور کنید که ما میخواستیم نظرات Jackson و Quincy را بشماریم، در اینجا با یک نگاه ساده میتوان به راحتی مشاهده کرد؛ اما با داشتن یک مجموعه بزرگتر سختتر از آنچه که تصور کنید خواهد شد.
GROUP BY در اصل به این کوئری میگوید که باید تمام رکوردهای Jackson را به صورت یک گروه و تمام رکوردهای quincy را نیز به عنوان یک گروه دیگر باشد. سپس تابع COUNT رکوردهای موجود در آن گروه را شمارش میکند و آن مقدار را برمیگرداند:

ظرف ۴ :کاربرانی را پیدا کنید که نظری ثبت نکردهاند
(جدید) مواد لازم
LEFT JOIN
IS NULL
متد
SELECT "Users"."username"
FROM "Users"
LEFT JOIN "Comments"
ON "Users"."id" = "Comments"."userId"
WHERE "Comments"."id" IS NULL;join های مختلف میتوانند بسیار گیجکننده باشند، بنابراین من این مبحث را اینجا باز نمیکنم. یک تفیک عالی در اینجا وجود دارد:Visual Representations of SQL Joins، که برخی از تفاوتهای سینتکسی بین انواع مختلف SQL را نیز شامل میشود.
اجازه دهید تا نسخه متفاوتی از این سؤال را باهم به سرعت تصور کنیم:
SELECT "Users"."username", "Comments"."id" AS "commentId"
FROM "Users"
LEFT JOIN "Comments"
ON "Users"."id" = "Comments"."userId";ما هنوز LEFT JOIN را داریم اما ستونی را اضافه کردهایم و بند WHERE را حذف کردهایم.
دادهی return شده ممکن است مانند این باشد:

بنابراین Jackson مسئول نظرات ۱ و ۲ ، Abbey برای ۳ و Quincy هیچ نظری ندارد.
تفاوت بین LEFT JOIN و INNER JOIN (چیزی که ما تابحال آن را فقط JOIN صدا میکردیم، که معتبر است) در این است که inner join فقط رکوردهایی را نشان میدهد که در آن مقادیر برای هر دو جدول وجود دارد. از طرف دیگر، left join همه چیز را از جدول اول یا سمت چپ (اونی که FROM داره) برمیگرداند، حتی اگر چیزی در جدول سمت راست نباشد. بنابراین inner join فقط رکورد Jackson و Abbey را نشان میدهد.
اکنون میتوانیم آنچه را که LEFT JOIN برمیگرداند را تجسم کنیم، آسانتر است که درباره بخشی که WHERE...IS NULL هست استدلال کنیم. ما فقط آن دسته از کاربرانی را برمیگردانیم که مقدار commentId آنها null است، و ما درواقع به ستونی که مقدار null دارد که در خروجی موجود است، نیاز نداریم، از اینرو چیز اصلی که حذف میشود آن است.
ظرف ۵ :لیست تمامی نظراتی که توسط هر کاربر در یک فیلد واحد اضافه شده، جدا شده است
(جدید) مواد لازم
GROUP_CONCAT یا STRING_AGG
متد (MySQL)
SELECT "Users"."username", GROUP_CONCAT("Comments"."comment" SEPARATOR " | ") AS "comments"
FROM "Users"
JOIN "Comments"
ON "Users"."id" = "Comments"."userId"
GROUP BY "Users"."id";متد (Postgresql)
SELECT "Users"."username", STRING_AGG("Comments"."comment", " | ") AS "comments"
FROM "Users"
JOIN "Comments"
ON "Users"."id" = "Comments"."userId"
GROUP BY "Users"."id";این دستورالعمل نهایی تفاوت syntax برای فانکشنی مشابه در دو موتور مشهور SQL را نشان میدهد.
خروجی مورد نظر ما:

در اینجا میتوانیم ببینیم که این نظرات گروهبندی شده و concatenated /aggregated که در یک زمینه یک رکورد، join شدهاند.
نوش جان
اکنون که برخی از دستورالعملهای SQL را یادگرفتهاید، خلاق باشید و ظروف داده خود را سرو کنید!
من دوست دارم به WHERE, JOIN, COUNT, GROUP_CONCAT به عنوان نمک، چربی، اسید و حرارت پخت پایگاه داده نگاه کنم (نویسندس دیگه، میخواد اینجوری فک کنه!! ). هنگامی که شما میدانید که میخواهید با این عناصر اصلی چه کاری انجام دهید یعنی؛ به خوبی روی آن مسلط هستید.
امیدوارم این مقاله برای شما مفید بوده باشد، از وقتی که برای مطالعه گذاشتید متشکرم.


در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید