
تشخیص انگشتان دست یک موضوع جذاب در حوزه پردازش تصویر میباشد. به ویژه هنگامی که در تعامل بین انسان و کامپیوتر کاربرد دارد.
در این مقاله قصد داریم تا روشی را توضیح دهیم که بتوان تعداد انگشتان دست را در فیلمی که توسط دوربین لپتاپ ضبط میشود تشخیص داد.
نگاه کلی
اساسا اولین کار تشخیص دست در یک فریم ویدئو است. این چالش برانگیزترین بخش کار است. روش پیشنهادی استفاده از دو روش حذف پسزمینه و HSV Segmentation برای ساخت یک ماسک است. وقتی که تصویر دست از فریم ویدئو جدا شد، حال میتوان تعداد انگشتان نمایش دادهشده را تشخیص داد. در اینجا دو متد پیشنهادی وجود دارد. اولین راه پیدا کردن بزرگترین حدفاصل در تصویر که میتوان آن را به عنوان دست فرض کرد میباشد. سپس نقاط محدب روی پوست و زاویه ایجاد شده را تشخیص میدهیم که احتمالا فاصله بین انگشتان میباشد. این راه یک روش دستی برای تشخیص تعداد انگشتان است. اما راه دوم استفاده از شبکه عصبی کانولوشنی همراه با ماسک برای تعیین تعداد انگشتان دست میباشد.
تشخیص دست
چالش برانگیزترین بخش، تشخیص دست در تصویر است. روشهای بسیاری برای انجام این امر وجود دارد؛ روشهایی نظیر Background Subtraction توسط lzane، HSV Segmentation توسط Amar Prakash Pandey، تشخیص با استفاده از Haar Cascade و همچنین استفاده از شبکههای عصبی. به هرحال ما قصد داریم تا در این مقاله درباره Background Subtraction و HSV Segmentation صحبت کنیم.
حذف پسزمینه (Background Subtraction)
در این روش اول از همه ما به یک پسزمینه بدون تصویر دست نیازداریم. برای پیدا کردن دست، ما میتوانیم تصویر دست را از پسزمینه جدا کنیم که این کار توسط کتابخانه OpenCV امکانپذیر است.
توجه داشتهباشید که کد تا حدی برای توضیح در اینجا آورده شدهاست. برای دسترسی به کد کامل آن را از پایین این مقاله دانلود کنید.
در آغاز، ما یک تفکیک کننده پسزمینه در هنگامی که پسزمینه واضح است میسازیم. منظور از وضوح یعنی زمانی که تصویر دست وجود ندارد.
bgSubtractor = cv2.createBackgroundSubtractorMOG2(history=10, varThreshold=30, detectShadows=False)بعد از اینکه تفکیک کننده پسزمینه ساخته شد، میتوانیم آن را بر روی تمامی فریمهای ویدئو اعمال کنیم.
def bgSubMasking(self, frame):
"""Create a foreground (hand) mask
@param frame: The video frame
@return: A masked frame
"""
fgmask = bgSubtractor.apply(frame, learningRate=0)
kernel = np.ones((4, 4), np.uint8)
# The effect is to remove the noise in the background
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel, iterations=2) # To close the holes in the objects
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_CLOSE, kernel, iterations=2)
# Apply the mask on the frame and return
return cv2.bitwise_and(frame, frame, mask=fgmask)در اینجا یک نمونه از تصویری که تفکیک پسزمینه شدهاست را مشاهده میکنید.

توجه داشته باشید که پسزمینه به صورت سیاه ماسک شده و از بین رفتهاست.
اما یک مشکل اساسی وجود دارد. تفکیک پسزمینه سبب میشود تا تمامی اشیاء متحرک به جز دست، در کل فریم حذف و نادیده گرفته شوند. از این رو روش دیگری را پیشنهاد میکنیم.
HSV Segmentation
در HSV (Hue, Saturation, Value) Segmentation، ایده جدا کردن تصویر دست بر پایه رنگ میباشد. در این روش ابتدا از رنگ دست نمونهبرداری و سپس تشخیص انجام میشود. معمولا یک پیکسل از فریم یا تصویر در قالب RGB (Red, Green, Blue) نمایان میشود. دلیلی که ما از HSV بهجای RGB استفاده میکنیم این است که RGB شامل اطلاعاتی از روشنایی پیکسل مربوطه است و از این رو وقتی که ما از رنگ دست نمونهبرداری میکنیم، ما روشنایی آن را به خوبی نمونهبرداری کردهایم. اما مشکل اینجاست که به هنگام تشخیص دست، باید تصویر دست زیر همان مقدار روشنایی باشد تا بتوان آن را تشخیص داد. روشنایی یک رنگ بصورت رمزگذاری شده در Value که یکی از پارامترهای HSV است، وجود دارد. از این رو وقتی ما از رنگ یک دست نمونهبرداری میکنیم، درواقع فقط از پارامترهای Hue و Saturation نمونهبرداری کردهایم.
برپایه تکنیکی که آقای Amar ارائه کرده است، ما تصویر دست خود را در مکانی قرار میدهیم تا بتوان نمونههایی از رنگ دست گرفت. با استفاده از پیکسلها، ما یک هیستوگرام تشکیل میدهیم تا فرکانس هر رنگ در نمونه را نشان دهد. این هیستوگرام احتمال توزیع رنگها را نشان میدهد.
با نرمالیزه کردن هیستوگرام، حال میتوانیم احتمال تشابه هر قسمت به رنگ دست را بدست آوریم.
handHist = cv2.calcHist([roi], [0, 1], None, [180, 256], [0, 180, 0, 256])
handHist = cv2.normalize(handHist, handHist, 0, 255, cv2.NORM_MINMAX)مقدار [0.1] در خط اول به این معنای گرفتن کانالها، رنگ (Hue)، اشباع (Saturation) و همچنین نادیده گرفتن کانال سوم یعنی مقدار (Value) میباشد.
مقدار [0, 180, 0, 256] دامنه تغییر مقادیر Hue و Saturation را معین میکند. مقدار Hue از 0 تا 179 متغییر است درحالی که مقدار Saturation از 0 تا 255 تغییر میکند.
پس از اینکه ما هیستوگرام نرمالایز شده از رنگهای دست را ایجاد کردیم، میتوانیم ماسک HSV را ایجاد کنیم. ماسک درواقع یک نقشه از احتمالها میباشد. هر پیکسل شامل احتمال تشابه خود به بخشی از تصویر دست میباشد.
def histMasking(frame, handHist):
"""Create the HSV masking
@param frame: The video frame
@param handHist: The histogram generated
@return: A masked frame
"""
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0, 1], handHist, [0, 180, 0, 256], 1) disc = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (21, 21))
cv2.filter2D(dst, -1, disc, dst)
# dst is now a probability map # Use binary thresholding to create a map of 0s and 1s
# 1 means the pixel is part of the hand and 0 means not
ret, thresh = cv2.threshold(dst, 150, 255, cv2.THRESH_BINARY) kernel = np.ones((5, 5), np.uint8)
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel, iterations=7) thresh = cv2.merge((thresh, thresh, thresh))
return cv2.bitwise_and(frame, thresh)پایین تصویری از نتیجه عملیات HSV Segmentation را مشاهده میکنید.

نکته منفی این تقسیمبندی این است که رنگ پوست دست نیز مشخیص میشود اما ما فقط دست را میخواهیم بنابراین، ما از عمل "bitwise and" در ماسک پسزمینه و ماسک HSV که همان تصویر دست میباشد، استفاده میکنیم. نتیجه ماسک نهایی ما است.
histMask = histMasking(roi, handHist)
bgSubMask = bgSubMasking(roi)
mask = cv2.bitwise_and(histMask, bgSubMask)شمارش انگشتها
بعد از اینکه ماسک نهایی را ایجاد کردیم، حال میتوانیم تعداد انگشتها را محاسبه کنیم. ما دو متد در اختیار داریم، اولی استفاده از روش دستی برای پیدان کردن مقادیر همرفتی است. و دومی استفاده شبکه عصبی کانولوشنی میباشد. ما روش دوم را انتخاب میکنیم.
شبکه عصبی کانولوشنی
استفاده از شبکه عصبی کانولوشنی (CNN) درواقع بسیاری از کارها را ساده میکند. کتابخانه Keras گزینه بسیار خوبی در پایتون است. کار با این کتابخانه نسبتا ساده است. به دلیل محدودیتهای حافظه GPU، اندازه فریم ویدئو را از 260*260 به 28*28 تغییر میدهیم. اگر شما از پردازنده GPU یا CPU قدرتمندی استفاده میکنید میتوانید اندازه ورودی مدل (Input Shape) را تغییر دهید اما پیشنهاد میکنیم اجازه دهید همین مقدار باقی بماند. در اینجا ما مدلی را طراحی کردهایم:
model = Sequential()
model.add(Conv2D(32, (3,3), activation=’relu’, input_shape=(28, 28, 1)))
model.add(Conv2D(64, (3,3), activation=’relu’))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(6, activation=’softmax’))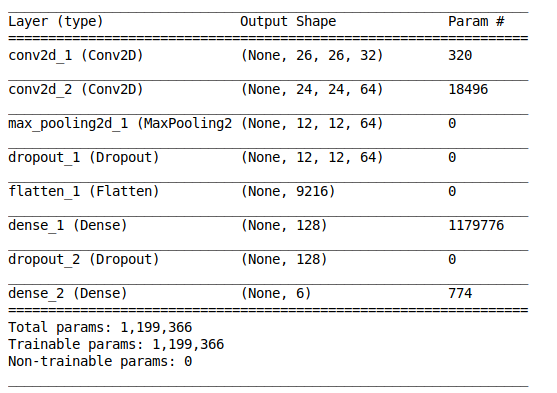
برای آموزش مدل، ما تقریبا از 1000 تصویر در هر کلاس و 200 تصویر برای تست استفاده کردیم. همچنین برای افزایش دقت مدل اعمالی نظیر تقارن، انتقال و دوران را روی تصاویر اعمال کردیم. برای اطلاعات بیشتر میتوانید سورس پروژه را برسی کنید.
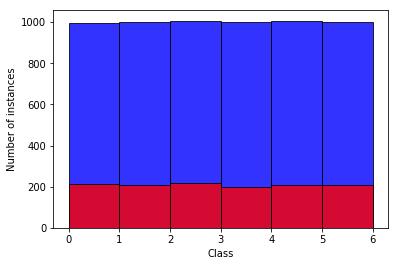
نکتهای که باید مورد توجه قرار گیرد، متعادل کردن تعداد دادههای هر کلاس است. برای مثال ما 6 کلاس داریم. هر کلاس یک عدد را نمایش میدهد برای مثال کلاس شماره 6 مربوط به مجموعه تصاویر از دست افرادی است که هر 5 انگشت خود را نمایش دادهاند. برای اینکه مدل آموزش داده شده متعصب نباشد باید تعداد دادههای هر کلاس تقریبا برابر باشد. نمودار زیر تعادل دادههای ما را نمایش میدهد.
در اینجا نمونههایی از دادههای آموزش ما آورده شدهاست. در بالای هر تصویر، کلاس مربوط به آن درج شدهاست.

نتیجه بسیار عالی بنظر میرسد. مدل در دوره پنجم از آموزش، دقت 99٪ را بدست میآورد. با این حال، این مدل از روی دست نویسنده مقاله آموزش داده شده و تست شده است که ممکن است این مدل به خوبی به دست افراد دیگر تعمیم دادهنشود. بنابراین، ما مدل خود را ارسال نمیکنیم. ما یک کارکرد برای ضبط تصاویر از دست خود پیادهسازی کردهایم. شما میتوانید خیلی ساده تصاویر آموزشی خود را تهییه کنید.

در نهایت ما میتوانیم مدل آموزش دیده را بارگذاری و استفاده کنیم.
from keras.models import load_modelmodel = load_model("model_1.h5")modelInput = cv2.resize(thresh, (28, 28))
modelInput = np.expand_dims(modelInput, axis=-1)
modelInput = np.expand_dims(modelInput, axis=0)pred = self.model.predict(modelInput)
pred = np.argmax(pred[0])نتیجه
با استفاده از نتیجه حاصل از تشخیص، میتوانیم از آن به عنوان فرمان تعامل با رایانهها استفاده کنیم (ما در پروژه پیوست شده کلیک کردن را پیادهسازی کردهایم). البته، شما میتوانید بیش از این کار کنید. با این حال، هنوز پیشرفتهای بسیاری برای عملی شدن این برنامه مورد نیاز است.


در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید