وارد شدن به دنیای یادگیری ماشین و هوش مصنوعی کار سادهای نیست. حتی افرادی که در این زمینه هم حرفهای هستند و متخصص به شمار میروند نیز نمیتوانند به روشنی مسیری را به شما برای یادگیری بدهند. این فیلدها به صورت مداوم در حال تغییر است و نیاز است که شما نیز خودتان را با این تغییرات وفق دهید. یکی از راهها برای همراه ماندن با این تغییرات و گسترشها این است که جوامع هوش مصنوعی و یادگیری ماشین را دنبال کنید و پروژههای متن باز آنها را مورد استفاده قرار دهید. این ابزارها به صورت روزانه در حال پیشرفت هستند بنابراین شما نیز باید خودتان را همراه با آنها حرفهای کنید.
در این مطلب ما قصد داریم به شما ۲۰ پروژه متن باز را معرفی کنیم که همگی میتوانند برای یادگیری ماشین و کاربردهایی از این دست مناسب باشند.
برخی از این ابزارها در طول چند سال گذشته مدام توسعه یافتهاند و میزان مشارکت کنندگان آنها تغییر کرده است. در این قسمت ابتدا سعی دارم تا تغییرات چند مورد از این کتابخانهها را از نظر تعداد مشارکت کنندگان بررسی کنم:
- TensorFlow با میزان ۱۶۹ درصد افزایش از ۴۹۳ مشارکت کننده در ۲۰۱۶ اکنون به ۱۳۲۴ نفر رسیده است.
- Deap با میزان ۸۶ درصد افزایش از ۲۱ مشارکت کننده در ۲۰۱۶ اکنون به ۳۹ نفر رسیده است.
- Chainer با میزان ۸۳ درصد افزایش از ۸۴ مشارکت کننده در ۲۰۱۶ اکنون به ۱۵۴ نفر رسیده است.
- Gensim با میزان ۸۱ درصد افزایش از ۱۴۵ مشارکت کننده در ۲۰۱۶ اکنون به ۲۶۲ نفر رسیده است.
- Neon با میزان ۶۶ درصد افزایش از ۴۷ مشارکت کننده در ۲۰۱۶ اکنون به ۷۸ نفر رسیده است.
- Nilearn با میزان ۵۰ درصد افزایش از ۴۶ مشارکت کننده در ۲۰۱۶ اکنون به ۶۹ نفر رسیده است.
ابزارهای جدیدی نیز که در ۲۰۱۸ معرفی شدهاند عبارت هستند از:
- Keras با ۶۲۹ مشارکت کننده.
- PyTorch با ۳۹۹ مشارکت کننده.
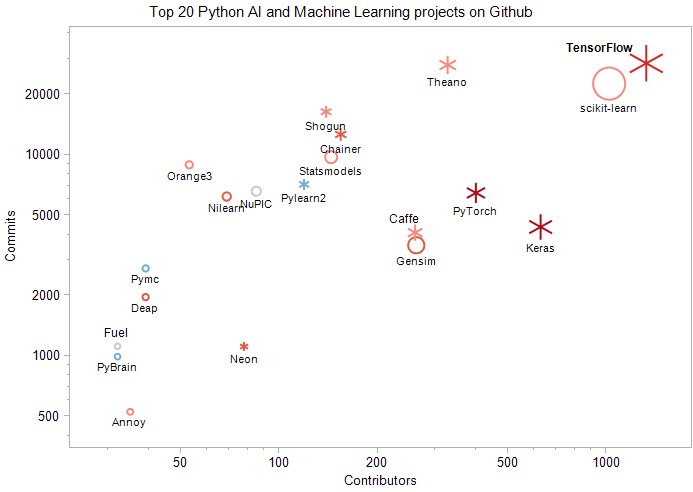
در تصویر بالا میتوانید آمار بصری را از تغییرات این پروژهها مشاهده بکنید. بزرگی از نظر اندازه در این آمار نشاندهنده تعداد مشارکت کنندگان است و رنگ در این نمودار مشخص کننده میزان تغییرات در تعداد مشارکت کنندگان است. رنگ قرمز بیشترین تغییر و رنگ آبی کمترین تغییر را نشان میدهد. شکلهای ستارهدار نمادی برای پروژههای یادگیری عمیق و دایره برای مباحث دیگر استفاده میشود.
در ادامه با ۲۰ پروژه متن باز برای یادگیری ماشین و هوش مصنوعی در پایتون همراهتان خواهیم بود:
۱. TensorFlow در اصل توسط Google Brain Team در واحد تحقیقات گوگل طراحی و ساخته شده است. هدف این سیستم آن بود که پروژههای تحقیقاتی را با سرعت بسیار بیشتری به نمونههای عملی تبدیل کرد. این پروژه ۱۳۲۴ مشارکت کننده، ۲۸۴۷۶ هزار کامیت و ۹۲۳۵۹ ستاره دارد.
۲. Scikit-learn ابزاری بسیار ساده و کاربردی برای کاوش و آنالیز داده است که در اختیار همگان قرار گرفته است. این ابزار براساس NumPy، Scipy و matpoltlib ساخته شده است. از آنجایی که این ابزار با لایسنس BSD منتشر میشود بنابراین میتوانید در پروژههای تجاری از آن استفاده کنید. این پروژه ۱۰۱۹ مشارکت کننده و ۲۲۵۷۵ هزار کامیت دارد.
۳. Keras یک API برای شبکههای عصبی سطح بالا است که با استفاده از زبان پایتون نوشته شده و قابلیت اجرا روی TensorFlow، CNTK و Theano را نیز دارد. این پروژه ۶۲۹ مشارکت کننده و ۴۳۷۱ هزار کامیت دارد.
۴. PyTorch یک کتابخانه شبکههای عصبی پویا و Tensor است که قابلیت استفاده از قدرت GPU را در اختیار دارد. این پروژه ۳۹۹ مشارکت کننده و ۶۴۵۸ هزار کامیت دارد.
۵. Theano به شما اجازه میدهد تا بتوانید عبارتهای ریاضی که شامل آرایههای چند بعدی میشوند را بهینه و ارزیابی کنید. این پروژه ۳۲۷ مشارکت کننده و ۲۷۹۳۱ هزار کامیت دارد.
۶. Gensim یک کتابخانه رایگان پایتون است که به شما قابلیت استفاده از مفاهیم آماری مقیاس پذیر، آنالیز سندهای متنی و… را میدهد. این پروژه ۲۶۲ مشارکت کننده و ۳۵۴۹ هزار کامیت دارد.
۷. Caffe یک فریمورک یادگیری عمیق است که براساس عبارات، سرعت و ماژولاریتی ساخته شده است. این ابزار توسط BVLC و جامعهای از مشارکت کنندگان توسعه داده شده است. این پروژه ۲۶۰ مشارکت کننده و ۴۰۹۹ هزار کامیت دارد.
۸. Chainer یک فریمورک متن باز مبتنی بر پایتون است که برای مدلهای یادگیری عمیق ساخته شده است. Chainer به شما اجازه میدهد تا بتوانید مدلهای گستردهی از یادگیری عمیق را پیادهسازی کنید. این پروژه ۱۵۴ مشارکت کننده و ۱۲۶۱۳ هزار کامیت دارد.
۹. Statsmodels یک ماژول پایتون است که به کاربران اجازه میدهد تا بتوانند مدلهای آماری را پیادهسازی بکنند، دادهها را کاوش و تستهای آماری را اجرا نمایند. در این ماژول لیست بزرگی از حالتهای آماده وجود دارد که میتوانند با دادههای مختلف استفاده شوند. این پروژه ۱۴۴ مشارکت کننده و ۹۷۲۹ هزار کامیت دارد.
۱۰. Shogun یک مجموعه ابزار یادگیری ماشین است که متدهای کاربردی و بهینهسازی شده یادگیری ماشین را در اختیار شما میگذارد. این ابزار به سادگی به شما اجازه میدهد تا بتوانید نمایش دادهها، کلاسهای الگوریتمی و ابزارهای چند منظوره متفاوتی را با همدیگر ترکیب کنید. این پروژه ۱۳۹ مشارکت کننده و ۱۶۳۶۲ هزار کامیت دارد.
۱۱. Pylearn2 یک کتابخانه یادگیری ماشین است. بیشتر کارایی این کتابخانه براساس Theano ساخته شده است. این بدان معناست که شما میتوانید پلاگینهای Pylearn2 که شامل عبارات و الگوریتمهای ریاضی میشود را بنویسید و با استفاده از Theano بهینهسازی کنید. این پروژه ۱۱۹ مشارکت کننده و ۷۱۱۹ هزار کامیت دارد.
۱۲. NuPIC یک پروژه متن باز مبتنی بر تئوری neocortex است که به نام HTM یا Hierarchical Temporal Memory شناخته میشود. بخشی از تئوری HTM را میتوانید از طریق این کتابخانه پیادهسازی کنید. البته این پروژه در حال توسعه و بزرگ شدن است. این پروژه ۸۵ مشارکت کننده و ۶۵۸۸ هزار کامیت دارد.
۱۳. Neon یک کتابخانه پایتونی برای یادگیری عمیق است. در تستهای مختلف این ابزار توانسته که تقریبا بیشترین کارایی را تحویل دهد. این پروژه ۷۸ مشارکت کننده و ۱۱۱۲ هزار کامیت دارد.
۱۴. Nilearn یک ماژول سریع و ساده آمارگیری پایتون روی دادههای Neurolmaging است. این کتابخانه برای آمارهای چندگانه از ابزار scikit-learn پایتون استفاده میکند. این پروژه ۶۹ مشارکت کننده و ۶۱۹۸ هزار کامیت دارد.
۱۵. Orange3 یک کتابخانه متن باز برای یادگیری ماشین و بصریسازی داده است که توسط مبتدیان و افراد حرفهای استفاده میشود. در این ابزار آنالیزهای دادهای تعاملی نیز پیادهسازی شده است که خود به عنوان یکی از کاربردیترین رویکردها در پایتون شناخته میشود. این پروژه ۵۳ مشارکت کننده و ۸۹۱۵ هزار کامیت دارد.
۱۶. Pymc یک ماژول پایتون است که برای پیادهسازی مدلهای آماری Bayesian استفاده میشود. در این کتابخانه چندین نوع الگوریتم دیگر نیز استفاده میشود. این ابزار برای بزرگ کردن اپلیکیشنها و مشکلات مختلف انعطافپذیر و توسعهپذیر است. این پروژه ۳۹ مشارکت کننده و ۲۷۲۱ هزار کامیت دارد.
۱۷. Deap را میتوان یک فریمورک انقلابی برای نمونهسازیهای سریع و تست کردن ایدهها است. با استفاده از این فریمورک میتوانید به سرعت الگوریتمها و ساختارهای دادهای مختلف را پیادهسازی بکنید. در این فریمورک همچنین پردازشهای موازی پیادهسازی شده است. این پروژه ۳۹ مشارکت کننده و ۱۹۶۰ هزار کامیت دارد.
۱۸. Annoy یک کتابخانه C++ است که با پایتون جفت شده است و میتواند در هر دو زبان استفاده شود. این ابزار ایجاد ساختارهای دادهای مبتنی بر فایل فقط خواندنی در حافظه را بسیار ساده میکند. این پروژه ۳۵ مشارکت کننده و ۵۲۷ کامیت دارد.
۱۹. PyBrain یک کتابخانه ماژولار برای پایتون است که هدف آن انعطافپذیری، سریع بود و قدرتمند بودن در امر پردازش است. همچنین در این ابزار قابلیت مقایسه الگوریتمها نیز پیادهسازی شده است. این پروژه ۳۲ مشارکت کننده و ۹۹۲ کامیت دارد.
۲۰. Fuel یک فریمورک مبتنی بر داده است که برای مدلهای یادگیری ماشین شما دادههای مناسبی را طراحی میکند. در کتابخانههای شبکه عصبی Blocks و Pylearn2 به خوبی توانایی استفاده از این فریمورک را دارید. این پروژه ۳۲ مشارکت کننده و ۱۱۱۶ هزار کامیت دارد.
تعداد مشارکت کنندگان و کامیتهای این پروژهها مبتنی بر آماری است که در فوریه ۲۰۱۸ گرفته شده است.

در حال دریافت نظرات از سرور، لطفا منتظر بمانید
در حال دریافت نظرات از سرور، لطفا منتظر بمانید